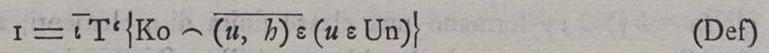The Entertaining history of the IT industry
Introduction
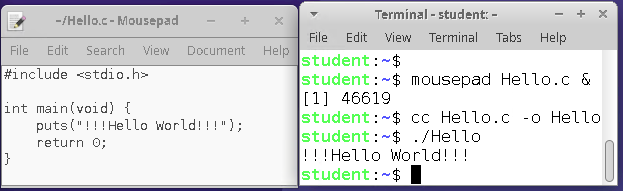
The website features books on relational database administration. If you're starting from scratch, databases can seem complex and uninteresting. Before learning database administration, it's usually recommended to start with SQL. A book on SQL is available on the website, but even this book can be daunting if you're studying on your own.
This book contains fascinating stories about the development of the IT industry to help us understand its origins and make IT great again, no doubt.
Part 1. History of Numbers
Unary number system
A number system is a representation of numbers using symbols. The oldest number system is the unary system. The unary system has a single digit, denoted by a unit, or dash. For example, the number three in the unary system can be written as three dashes: ||| . The unary system is "positionless," meaning the position of the dash (first or second in order) does not affect the number (the sum of the dashes) represented by the dashes. The unary system is used:
1) when teaching counting in elementary grades of school using counting sticks;
2) when using notches to keep a calendar where there is no paper. Robinson Crusoe in Daniel Defoe's novel made notches on a wooden post to count the days;
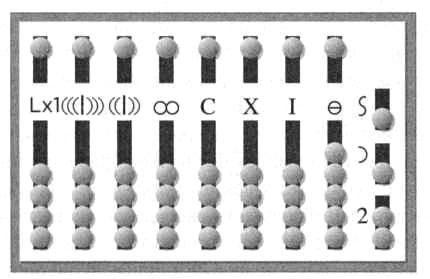
3) to display the level on the indicators:
4) to designate numbers within sexagesimal digits in the Babylonian numeral system.
Numbers were used to count objects and perform calculations. For example, how many servings of food would be needed to feed three pets for a week, assuming each pet eats one serving per day? 7 x 3 = 21 servings would be needed. Calculations were performed manually or with improvised means, such as laying out sticks or pebbles.
Duodecimal number system
The duodecimal number system originated from counting each phalanx of the four fingers of the same hand using the thumb. Duodecimal finger counting is now common in India, Pakistan, Afghanistan, Iran, Turkey, and Iraq.
------------
The first three powers of 12 have their own names: dozen = 12; gross = 12 dozens; mass = 12 grosses. Twelve plates are a "dozen plates." Small items, such as paper clips, were sold in grosses, 12 x 12 = 144 pieces. The phrase "massa narodu" (mass of people) denoted not weight, but the number of people: at least 12 x 12 x 12 = 1728 people.
-------------
The convenience of the duodecimal system is that the number 12 has many factors: 2, 3, 4, 6. This means that duodecimal numbers are easier to divide without a remainder and can be done without fractions. The duodecimal number system is compatible with the sexagesimal system, since 12 is a factor of 60.
In ancient Rome, an ounce was 1/12 of a unit of weight called a libra (meaning "scale"). The modern pound is abbreviated as "lb," which is an abbreviation of libra. The English system of measurement is based on the Roman numeral system. In the 20th century, the English system of measurement began to be replaced by the metric system, which is based on the decimal system.
Sexagesimal number system
The sexagesimal numeral system was used in Babylon two thousand years BC. This numeral system arose as a combination of the duodecimal and quinary systems, as the Sumerian names for the numbers 6, 7, and 9 bear traces of a quinary system. Roman notation also used letters to denote fives: I = 1, V = 5, X = 10, L = 50, C = 100, D = 500, M = 1000. For fractions, the Roman system used the symbols S = 1/2 and Ɔ = 1/12 (ounce). The following symbols were used to write numbers:
" | " to denote units;
" < " to denote tens within the sexagesimal digit;
" |- " to denote the number 100;
" <|- " to denote the number 1000.
An example of writing the number 23: " <<||| ". Why do the symbols have such a unique shape? The symbols were applied with a triangular stick (wedge) to wet clay and were an imprint of the wedge. Therefore, Babylonian writing is called cuneiform. An example of an ancient handbag and cuneiform text:
The Babylonian system had no symbol for zero, which led to ambiguous notation of numbers. The meaning of the numbers had to be inferred from the context or from the spaces between the symbols. Later, between the 6th and 3rd centuries BCE, the symbol for zero appeared as the " \\ " symbol, but was used only in the middle of sexagesimal numerals to denote empty places. At the end of a number, zero symbols were used only for astronomical calculations. An example of notation for numbers from 1 to 59 in the Babylonian sexagesimal system:
The sexagesimal system was used by ancient Greek astronomers to measure the angular coordinates of stars. Elements of the Babylonian sexagesimal system have survived to this day and are used to measure time and angles: there are 60 minutes in an hour and 360 degrees in a circle.
Astronomers have always needed precise calculations. With the development of seafaring, precise calculations became necessary for navigation. After the invention of smokeless gunpowder in the 19th century, which allowed projectiles to fly long distances, precise calculations became necessary for calculating projectile trajectories (ballistics). Over large distances, errors accumulate in calculations and distort results, so methods for improving accuracy were sought. The need for precise calculations fueled the development of mathematics and led to the creation of computers.
Decimal number system
In positional number systems, the value of each symbol depends on its position ("place value"). The Babylonian system is positional, but each number is written in "additive" (non-positional) form. One of the problems with this notation was that indentation (spaces) had to be used to distinguish which number was being represented. An example of writing two numbers in the Babylonian system: " | | " = 61, " || | " = 121.
The first evidence of the use of the decimal number system was found in India and dates back to 595. The main advantage of the system was that it had a sign for zero, and most importantly, this sign was used at the end of the number (final position).
The number 10, as the base of the number system, was chosen based on the number of fingers on both hands that could be used to count by bending the fingers and showing the number with both hands. One finger represented one in the unary system.
The decimal system came to the Arab world from India. Al-Khwarizmi described the Indian system of numeration in his book, which was later brought to Europe. The simple and convenient rules for adding and subtracting numbers in the decimal positional system made it popular. Al-Khwarizmi's book was written in Arabic, so the decimal system became known in Europe as Arabic, and Indian numerals became known as Arabic numerals. Arabic numerals gradually replaced Roman numerals and other non-positional systems. Positional notation using Arabic numerals in the decimal system has advantages over Roman numerals because:
- it is more compact than the Roman one;
- it allows you to visually compare numbers by size;
- it has simple methods of multiplication and division.
It's difficult to write large numbers in Roman numerals, and fractions aren't written at all. The transition to Arabic numerals and the decimal system accelerated the development of mathematics.
Letters and numbers
Before the advent of Arabic numerals, numbers were represented by letters of the alphabet. There were no symbols for numbers.
Abraham ( the founder of three religions), observing the stars, concluded that there is a single force.
Quran 6:76 says: When it became dark, he saw a star and said: This is my Lord. But when it set, he said: I do not worship what sets.
In the Bible, Genesis chapter 26:5, it is written: “ So Abraham heard My voice.”
The Babylonian Talmud states: “Ami son of Aba said: Abraham was 3 years old when what is written (in Genesis 26:5) took place,” and provides calculations using the gematria method.
In gematria, each letter has its own numerical value. The "gematria" of a word is the sum of the numerical values of the letters in the word. If words have the same gematria, it is considered to be semantically related. The gematria of the word ( עֵ֕קֶב , consists of three letters, pronounced " ekev ") is 70 + 100 + 2 = 172. This means Abraham heard the voice in 172 years. Abraham lived 175 years. This means Abraham heard the voice in 175 - 172 = 3 years.
Gematria has analogues in other alphabets: Akshara-Sankhya in Indian (Devanagari), Abjadiya in Arabic.
In the desert (or mountains), on a cloudless night, the stars are clearly visible from one end of the sky to the other. The sight of the starry sky inspired little Abraham, and he asked, "Who created This?" (pronounced "Mi bara Ele"). The question became a statement that someOne created it.
Before Abraham, people saw the same sky, but they hardly paid attention to its beauty, perhaps because they did not see any benefit in it for their difficult life in the ancient world, and its appearance did not awaken mental activity in them.
-------------
The Starlight Headliner has been available to Rolls-Royce passengers since 2003, starting with the Phantom VII:
-------------
Zero
Roman numerals lack a symbol to represent zero. In Europe, before the advent of Arabic numerals, Roman numerals were used, and the lack of zero hampered the development of mathematics. Instead, the words nulla or nullae (meaning "no") were used.
The use of zero and operations with zero was first studied and described by the Indian astronomer and mathematician Brahmagupta in 628. His work, "Brahma-sphutasiddhanta," has come down to us, and is translated as "The Doctrine (digest, canon) of the manifestation (manifestation, teaching) of Brahma." The work describes the "mathematics of procedures" (algorithms), the "mathematics of seeds " ( equations ), arithmetic operations, series, and proportions (fractions).
------
According to the Guinness Book of World Records, the longest unit of time measurement is the Indian "kalpa" (a "day of Brahma," equal to 4.32 billion years). This unit of measurement is described in the Puranas (ancient tales) written between the 3rd and 12th centuries.
------
Brahmagupta defined zero as the result of subtracting the number itself from a number. In modern algebra, zero is defined as the "neutral element" with respect to the operation of addition: a + 0 = 0 + a = a . In addition to addition, zero is also neutral with respect to subtraction. One is the "neutral element" with respect to the operations of multiplication, exponentiation, and division.
Brahmagupta described the rules of arithmetic operations on positive, negative numbers, and zero, viewing positive numbers as property and negative numbers as "debt." Brahmagupta even defined division by zero:
Zero divided by zero is zero;
Dividing a positive or negative number by zero is equal to a fraction with zero in the denominator;
Dividing zero by a positive or negative number equals zero.
Unit
In ancient times, mathematicians also singled out the number 1, considering it not even a number, but a distinct concept. The ancient Greek mathematician Euclid, who lived around 300 BC, first defined one, and then defined "number" as a set of ones. According to his definition, one is not a number, and unique numbers do not exist. For example, any two ones in a set of ones equal the number 2.
When using the binary number system, the ambiguities disappear, but at that time the binary number system had not yet been invented; it only appeared in 1703.
----------------
Academician, Doctor of Physical and Mathematical Sciences, Professor Zhuravlev wrote in his book "Fundamentals of Theoretical Mechanics":
It's noteworthy that the formula given in Poincaré's book "Science et Méthode" differs from the one given in Burali-Forti's article "A Question of Transfinite Numeri." Two vinculum symbols (the dashes at the top) are missing:
One might assume that the vinculum denotes a grouping of elements and the symbol could be omitted, but the line continues above the epsilon and cannot be omitted without reason. Burali-Forti's first line was also not added for aesthetic reasons. The complex notations and intricate definitions that mathematicians use help them discover something new, to look at mathematical concepts from a different perspective. If Burali-Forti's elaborate definition of the unit helped him discover the "Burali-Forti paradox," then such notations and chains of logical inferences were useful to him. For other mathematicians, his notations are useless because Burali-Forti had likely already discovered everything that could be discovered with them. Therefore, Poincaré and Zhuravlev did not delve into Burali-Forti's notations. When teaching mathematics, they strive to use the simplest possible notations and definitions, but this is not always successful.
----------------
In 1960, the US Navy developed the KISS (Keep It Simple, Stupid) design principle: the simpler a system is, the better it performs. This principle prohibits the use of more complex tools than necessary to solve the problem. This principle applies to both design and software development.
French mathematician André Weil told mathematician Vladimir Arnold that he and his classmates, after completing their studies, concluded that the entire teaching of mathematics was incomprehensible from the very beginning and needed to be rewritten. They set about this rewriting, creating a group called "Nicola Bourbaki."
----------
To represent the empty set, Bourbaki introduced the symbol Ø (a crossed zero), which came to be used to represent zero in computer fonts to avoid confusion with the letter "O", which looks like zero.
----------
Notations and the rules for their use influence the ease of learning. This applies to any field, including mathematics and computer science.
Natural numbers
Positive integers are historically called "natural" because they arise naturally when counting objects. Natural numbers are used to describe the number of objects and the ordinal position of an object.
There are two approaches to defining natural numbers:
1) define them as numbers arising when numbering (counting) objects: first, second, third, fourth, fifth. In this approach, the series of natural numbers begins with one. Ordinal numbers were invented by the mathematician Cantor. His approach was called naive set theory because the mathematician Burali-Forti discovered a paradox in it, which was named the "Burali-Forti paradox."
2) define them as numbers arising when designating the quantity of objects: 0 objects, 1 object, 2 objects, 3 objects, 4 objects, 5 objects. With this definition, the series of natural numbers begins with zero. This approach is used by Bourbaki. The presence of zero facilitates the formulation and proof of arithmetic theorems.
Until the 20th century, mathematicians were unable to decide whether zero should be considered a natural number. The International Organization for Standardization (ISO) helped them with this. In 1992, ISO issued standard ISO 31-11, "Mathematical notations and symbols for use in natural sciences and technology," which specifically stipulated that the symbol ℕ denotes "the set of natural numbers, including zero ." The last two words ended centuries of ambiguity, and zero took its place among the natural numbers.
The number of elements is called the cardinality or the cardinal number of a set of objects. Cardinality is denoted by the letter aleph ﬡ . The cardinality of the set of natural numbers ℕ is denoted by "aleph-zero" ﬡ ̥
-------
On August 11, 1982, Edsger Dijkstra, the first Dutch programmer, published the paper EWD831 (he numbered his papers with his initials and a serial number) "Why Numbering Should Start at Zero".
In most programming languages, the numbering of elements in arrays, collections, and characters in strings starts with zero (C, C++, Java, Python), but some languages use different rules. In Lua and MATLAB, array numbering starts with one, and in the Algol programming language, when defining an array of the form a[0:3] , the numbering starts with zero, and when defined as a[3] , the numbering starts with 1.
Dijkstra makes the argument from a practical standpoint: "Extensive experience with the Mesa programming language has shown that the use of the other three rules has been a constant source of awkwardness and errors, and on the basis of this experience, Mesa programmers are now strongly advised not to use them."
Dijkstra's article was prompted by an incident in which, in an emotional outburst, a university mathematics professor (who was not a computer scientist) accused several young computer science professors of "pedantry" because (out of habit) they started numbering from zero. The mathematician took this conscious adoption of the most reasonable convention as a provocation.
The difference in array numbering is probably due to the fact that the developers of some languages thought of an array element pointer as an offset from the beginning of the array, while the developers of other languages thought of the pointer as the ordinal number of the array element.
---------
Ancient games
In ancient times, boards with pieces (counters) were used for games, as there were no computer games. In the 1980s, computer games contributed to the widespread use of home computers. An example of an ancient game is the ancient Egyptian board game of moving pieces around a board called "senet" ( c ⲓⲛⲉ , "passage"), known since 3500 BC.
The pronunciation of the game's name is unknown, as are any words in the Egyptian language. The oldest complete senet set was found in the tomb of the physician Hesy-Ra, librarian to the Pharaoh Geser, at Saqqara (Third Dynasty, 2686 BC). As with many games, winning senet depended on a combination of skill (strategy) and chance (luck). The random element was introduced into the game by a "random number generator"—the throwing of four sticks. The sticks used were flat, one side black, the other white.
After the sticks were thrown, the score was calculated: one stick landing white side up scored 1 point and an extra throw; two scored 2 points; three scored 3 points; four scored 4 points and an extra throw. If all the sticks landed black side up, the score was 5 points and an extra throw (this was the maximum score). The score determined how many moves the pieces could be moved.
Then the player's skill came into play: they could use points to move five pieces, one, or several. The outcome of the game depended on the players' skill and chance (luck).
Senet of Pharaoh Amenhotep III
In ancient Rome, they played "tabula" (derived from the Greek word τάβλη, board), which is the predecessor of the modern game "backgammon".
Tabula board diagram
In tabula they threw dice, not sticks.
--------
In the three-dimensional world, there are five "regular" polyhedra (the "Platonic solids")—those with spatial symmetry and identical faces. One of them is a cube with six square faces. The other three have four, eight, and twenty triangular faces, and one has twelve pentagonal faces.
There are six regular polyhedra in 4-dimensional space.
In spaces with a higher number of dimensions there are three regular polyhedra.
The Frobenius theorem and the Hurwitz theorem are related to spaces. The vector product is uniquely defined only in three-dimensional space and is described by quaternions.
Memorial plaque: While walking here on October 16, 1843, in a flash of genius, Sir Hamilton discovered the formula for multiplying quaternions.
For dualism there is an algebra of octonynons, but their product lacks associativity.
----------
Games from the "mancala" (منقلة, man qalah ) family were played in Africa and Asia. This is a game for two players who move grains, seeds , stones, and pebbles through holes. Qalah is a modern game from this family. The game board:
The game of Kalakh was implemented on the BESM-6 (Large Electronic Calculating Machine) computer. The BESM-6 had a dialog program called Genie. The computer user played against the program. The player and the program had:
6 holes - playing fields,
There is one large hole called qalah into which the stones must be moved.
Initially, the stones are distributed equally across all the playing holes.
---------
The fine structure constant is a dimensionless number approximately equal to 1/137.035999. It determines the strength of the interaction between electrons and nuclei of atoms. If the constant were greater by 4%, stars would be unable to produce carbon and heavier elements.
---------
Algebra
Brahmagupta's book reached Baghdad, where it was translated into Arabic. In the 9th century, the scholar (astronomer, geographer, historian, translator, philosopher, and mathematician) al-Khwarizmi wrote the book "Kitab al-jabr wa'l-muqabala" (Book of Addition and Subtraction). The word " algebra " derives from the book's title . Al-Khwarizmi described the Indian positional decimal number system and formulated rules for calculation, including for zero. He translated the Indian word for zero as as-sifr or simply sifr, from which come the words "digit" and "cipher."
Al- Khwarizm was the first person to consider algebra as an independent discipline, and also the first to teach algebra in a simple form (literally "from scratch"), therefore he is recognized as the founder of algebra.
Al-Khwarizmi was born in the city of Khiva in the Khorezm region in 783. Khiva is now in Uzbekistan. In 783, al-Khwarizmi moved to Baghdad, where he headed the Bayt al-Hikma (House of Wisdom, analogous to modern Academies of Sciences), founded by Caliph al-Ma'mun, the son of Harun al-Rashid, who was mentioned in the book "A Thousand and One Nights" (Kitab al-f layla wa layla).
Al-Ma'mun is notable for being the first person since the construction of the pyramid of Pharaoh Khufu (the pronunciation of Egyptian words is unknown; the Greeks wrote the pharaoh's name as Sufis->Saofis->Cheops) to enter the Great Gallery of the Pyramid of Cheops in 831. Al-Ma'mun was a patron of scholars and commissioned the translation of Ptolemy's Almagest into Arabic.
----------
The Almagest (from the Arabic al- Majisti ), " The Great Mathematical Construction of Astronomy in 13 Books," is a work by Claudius Ptolemy, created around 140 CE and comprising all known astronomical knowledge of Greece and the Middle East at the time. For 13 centuries, the Almagest remained the foundation of astronomy.
The Almagest came to Europe during the Renaissance in Arabic translation.
----------
A century after al-Khwarizmi, al-Biruni and his colleague Ibn Sina (Avicenna) worked at Bayt al-Hikma. In 1000, al-Biruni, in his work "Chronology, or the Monuments of Past Generations," described all the calendars known to him and compiled a chronological table of all eras, beginning with the biblical patriarchs.
In the first half of the 12th century, al-Khwarizmi's book reached Europe in a Latin translation. Along with al-Khwarizmi's book, Indian numerals, which became known as Arabic numerals, arrived in Europe. The book began with the words: "Dixit algorizmi" (Al-Khwarizmi said), which is where the word "algorithm" comes from.
The Book of Changes
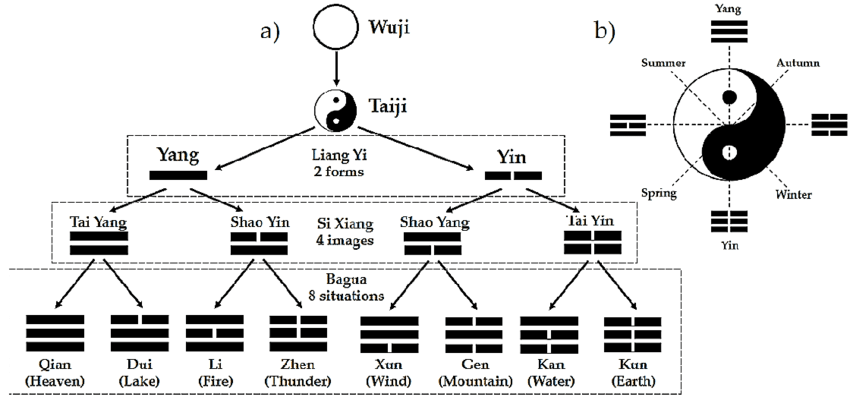
The Book of Changes (I Ching) is a Chinese philosophical text dating back to approximately 700 BC. The text of the book is notable for its use of binary symbols: the horizontal bar and the broken line. The text of the book contains 64 symbols, designated by 6 digits. In modern binary notation, the symbols could be designated by binary numbers: 000000 =䷁, 000001 =䷗, 000010 =䷆, 000011 =䷒. The symbols are called "hexagrams" from the word hexa (six). Hexagrams consist of two trigrams. Each trigram and hexagram has its own name, meaning, and interpretation.
The hexagram (6 divided into 3 and 2) is also represented as three pairs of two lines. In ancient Chinese philosophy, there are three elements: heaven, man, and earth. The first pair of lines, starting from the bottom, symbolizes earth, the second pair symbolizes man, and the third pair symbolizes heaven.
From infinity (Wuji - nothingness, denoted by a circle—the symbol of zero) a division is created into two opposites (Taiji). One side (Yang) is denoted by a line, the other side (Yin) by a broken line. They are then combined, producing four combinations, each consisting of two lines. Then they are combined again, producing eight combinations of three lines (trigrams).
The trigram and hexagram symbols are present in the modern universal character encoding scheme Unicode, these are symbols from 2630 to 2637 and from 19904 to 19967.
In the binary number system, six digits allow us to store 2^6 (two to the power of six) = 64 values. One byte consists of 8 bits and stores 2^8 = 256 values.
Binary number system
The binary number system was first described in 1703 by the German scientist Leibniz in his article "Binary Arithmetic Explanation." Leibniz coined the term "function," became the founder of mathematical analysis, and was the first president of the Berlin Academy of Sciences. Leibniz was the first to use the period "·" to denote multiplication, as the cross symbol " × " could be confused with a variable denoted by the letter " x ." In programming languages, the symbol " * " is used for multiplication . The opposite was true for the division symbol. Leibniz began using the symbol " : " for division to avoid confusion with the fraction notation, which was popular in mathematical articles at the time. The colon proved an unsuccessful replacement, as it is used in ordinary text. To avoid ambiguity, the symbol " ÷ " began to be used, but this symbol did not gain widespread use and is not found on computer keyboards.
In programming languages, fractions are not used as a data type, therefore in programming languages the division operator is denoted by the symbol " / ".
Leibniz's inspiration for binary arithmetic came from his acquaintance with the Chinese Book of Changes, which he learned about through his correspondence with the missionary and cartographer Bouvet. Leibniz noted that the hexagrams of the Book of Changes correspond to binary numbers from 000000 to 111111.
The binary system is convenient for performing arithmetic operations. For example, addition has three rules: 0 + 0 = 0 ; 0 + 1 = 1 ; 1 + 1 = 0 and carry 1 to the most significant digit.
tables of addition, subtraction, and multiplication from Leibniz's article "Explanation of Binary Arithmetic"
--------------
Gottfried Leibniz was born on July 1, 1646. At the age of six, he lost his father, a professor of ethics at the University of Leipzig. His father left behind a large library.
Leibniz's teacher noticed his student reading books and went to complain to Gottfried's relatives, asking them to address his "inappropriate and premature" reading of books, which, in his opinion, were beyond his age. He would have convinced Leibniz's relatives of this, if a scholar and well-traveled nobleman who lived nearby hadn't accidentally overheard the conversation.
Struck by the teacher's hostility, who judged everyone by the same standard, he said it would be foolish to limit the boy's interest in science and that his thirst for knowledge should be encouraged. Just in case, Gottfried was invited. He answered the nobleman's questions correctly, and the nobleman forced Leibniz's relatives to promise that Gottfried would be given access to his father's library and allowed to read whatever he wanted.
As Leibniz wrote: "I was as triumphant as if I had found a treasure, for I was burning with impatience to see the ancients, whom I knew only by name - Cicero and Quintilian, Seneca and Pliny, Herodotus, Xenophon and Plato, the writers of the time of the Emperor Augustus and many Latin and Greek Fathers of the Church. All this I began to read, according to my inclination, and enjoyed the extraordinary variety of subjects. Thus, before I was twelve years old, I understood Latin fluently and began to understand Greek."
His father's library allowed Leibniz to study books he would have had access to only during his student years. By the age of 12, Leibniz was proficient in Latin, and at 13, he began writing poetry. He graduated from high school at 14, and at 15, he entered the University of Leipzig, where his father taught.
--------------
It's hard to say whether Leibniz would have become a scientist without the difficulty of accessing books, which fueled his desire to obtain what he desired. Nowadays, access to a vast amount of information is easy, thanks to the internet and search engines. While reading books, you might come across an unfamiliar term, and its description can easily be found online. On the other hand, with the abundance of information, the importance of books is diminished, and the desire to understand what they contain diminishes.
Abacus
To count numbers in Roman notation, a Roman abacus was used. The word can be interpreted as "a board with grains of sand" ( seeds , grains, stones, pebbles). The prototype of the Roman abacus can be considered a board with lines (indentations) into which stones (stones) were placed, which was used in Babylon over 3000 BC.
Roman abacus
China also had an abacus, called a "suanpan." The first mention of a Chinese abacus dates back to 190. The earliest depiction of a Chinese abacus appears in an ancient Chinese primer from 1371. An example of a Chinese abacus:
---------
From the book by Nobel Prize-winning physicist Richard Feynman, Surely You're Joking, Mr. Feynman:
And then it dawns on me: he doesn't know numbers. When you have an abacus, you don't have to memorize a bunch of arithmetic combinations; you just learn to click the tiles up and down. You don't have to remember that 9 + 7 = 16; you just know that when you add 9, you move the decimal tile up and the ones tile down. So we do basic arithmetic more slowly, but we know numbers.
Moreover, the very idea of an approximate method of calculation was beyond his comprehension, despite the fact that it is usually impossible to calculate a cube root exactly.
---------
Calculating machines (arithmometers)
Arithmometers are mechanical devices that perform arithmetic operations on numbers. For a device to be considered an arithmometer, it is sufficient for it to be able to add numbers.
The first arithmometer was created by Wilhelm Schickard in 1623. His arithmometer performed four arithmetic operations on six-digit decimal numbers. Schickard made two copies of the arithmometer. One was intended for the astronomer and mathematician Kepler, who is famous for his discovery that the planets move along elliptical curves rather than in circles. Both arithmometers were destroyed in a fire, but the arithmometer drawings survived and established Schickard's claim to the arithmometer's invention.
Blaise Pascal created the second arithmometer in 1962, when he was 19 years old. His father was a tax collector and often performed lengthy calculations. Blaise wanted to automate this tedious task so that his father could spend more time with the family. At that time, financial calculations were conducted in monetary units called livres, sous, and deniers. The difficulty wasn't in the names, but in the fact that a livre was divided into 20 sous, and a sou was divided into 12 deniers. The arithmometer, however, used the decimal system and was not very convenient for calculations, so it was not widely used. Blaise Pascal built only 50 arithmometers.
The third arithmometer was invented by Leibniz in 1673. He decided to create an arithmometer after the mathematician, astronomer, and first president of the French Academy of Sciences, Huygens, complained that he had to perform many tedious calculations.
Schickard, Pascal, and Leibniz created their arithmometers independently of each other, and therefore can be called the inventors of the arithmometer.
More complex calculating machines were developed much later. The technology of the time didn't allow for the creation of complex mechanisms at a reasonable cost. The first commercially successful arithmometer was invented in 1820, went on sale in the 1840s, and only became widely available in the late 1870s. This arithmometer was designed by Charles-Xavier Thomas, who received the French Legion of Honor for his invention.
In 1822, Babbage built a model of a calculating machine that calculated the values of mathematical functions using Newton's interpolation formula by the finite difference method, so he called the calculating machine a difference engine.
The first computer project
In 1833, Babbage decided to create a universal computing engine, which he called the Analytical Engine. It included an arithmetic unit, which Babbage called a "mill"; a memory unit for storing 50 numbers ("warehouse"); and input/output devices using punched cards. The Difference Engine could only perform one task, while the Analytical Engine could execute arbitrary tasks (programs), making it the design for the first computer in history. This machine was to consist of 25,000 parts—gears and rotating cylinders—and be driven by a steam engine. The technology of the time did not allow for the construction of a machine of such complexity.
Computers became possible to create only with the advent of electricity on electrical relays, lamps and semiconductor elements.
Ada Lovelace
Babbage was assisted by Augusta (Ada) Lovelace, born December 10, 1815. Ada described an algorithm for calculating Bernoulli numbers on the Analytical Engine, introducing the concepts of loops, variables, and variable initialization. This was the first program written to run on a computing machine, making Ada Lovelace the first programmer in human history.
-----------
Ada had been fascinated with mechanics since childhood, and at the age of 12, she decided to design a flying machine. She began by designing wings. She studied materials including paper, oiled silk, wire, and feathers. To determine the wing size and shape, she studied bird anatomy. At 12, Ada wrote a book to remember her findings.
-----------
The first computer program
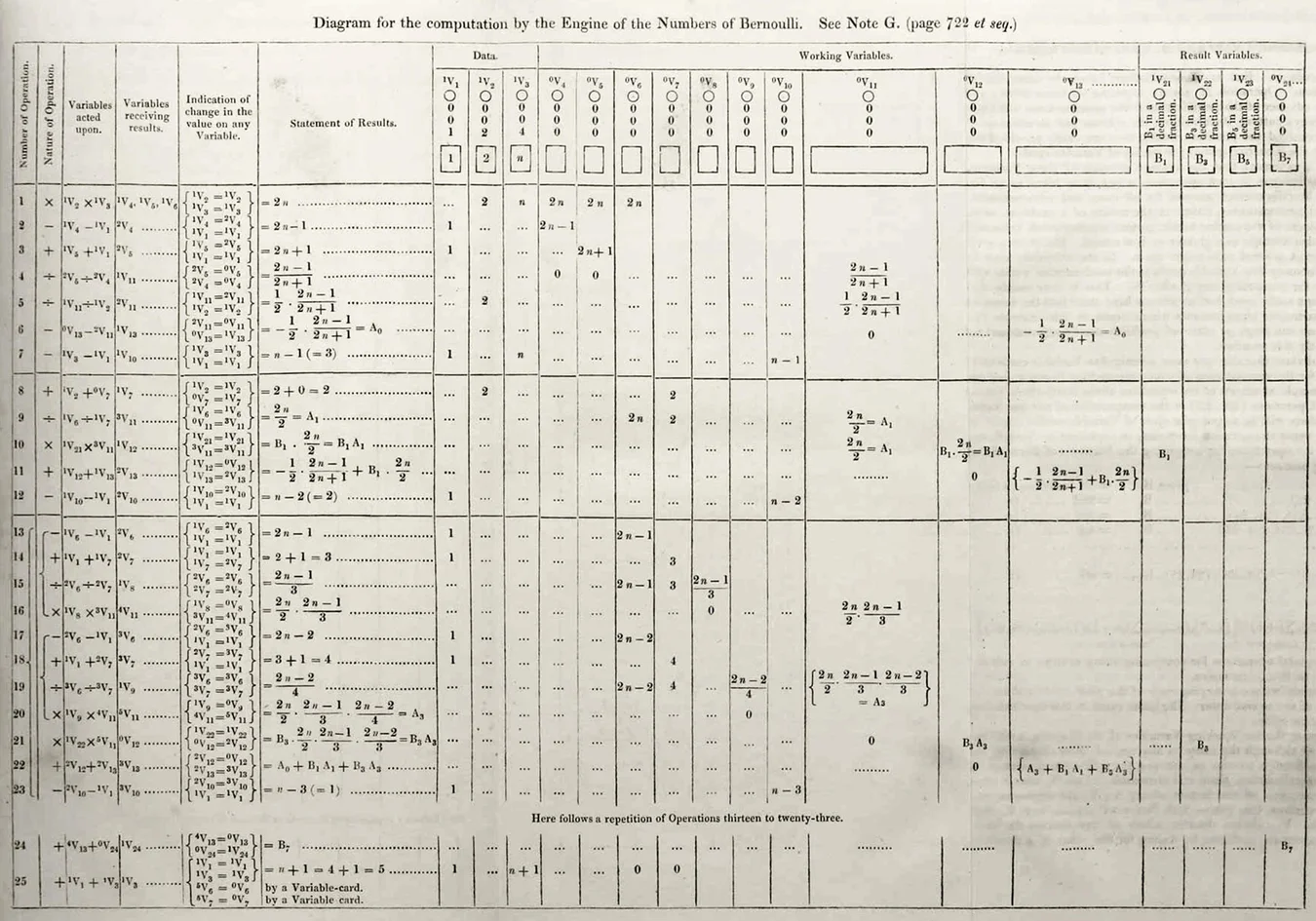
At 28, Ada published a paper on the Analytical Engine under the pseudonym AAL. The paper presented a 25-step computational program, including loops:
Each program step specifies which operation is performed on which variables, and which variable the result is written into. Cycles are indicated by curly brackets. The final result of the Bernoulli number B7 calculation is written into variable V24 at step 24.
The priority of the first error (bug, pronounced as "bug") in a computer program also belongs to Ada: in the 4th row, 3rd column, instead of V5/V4, it should be V4/V5.
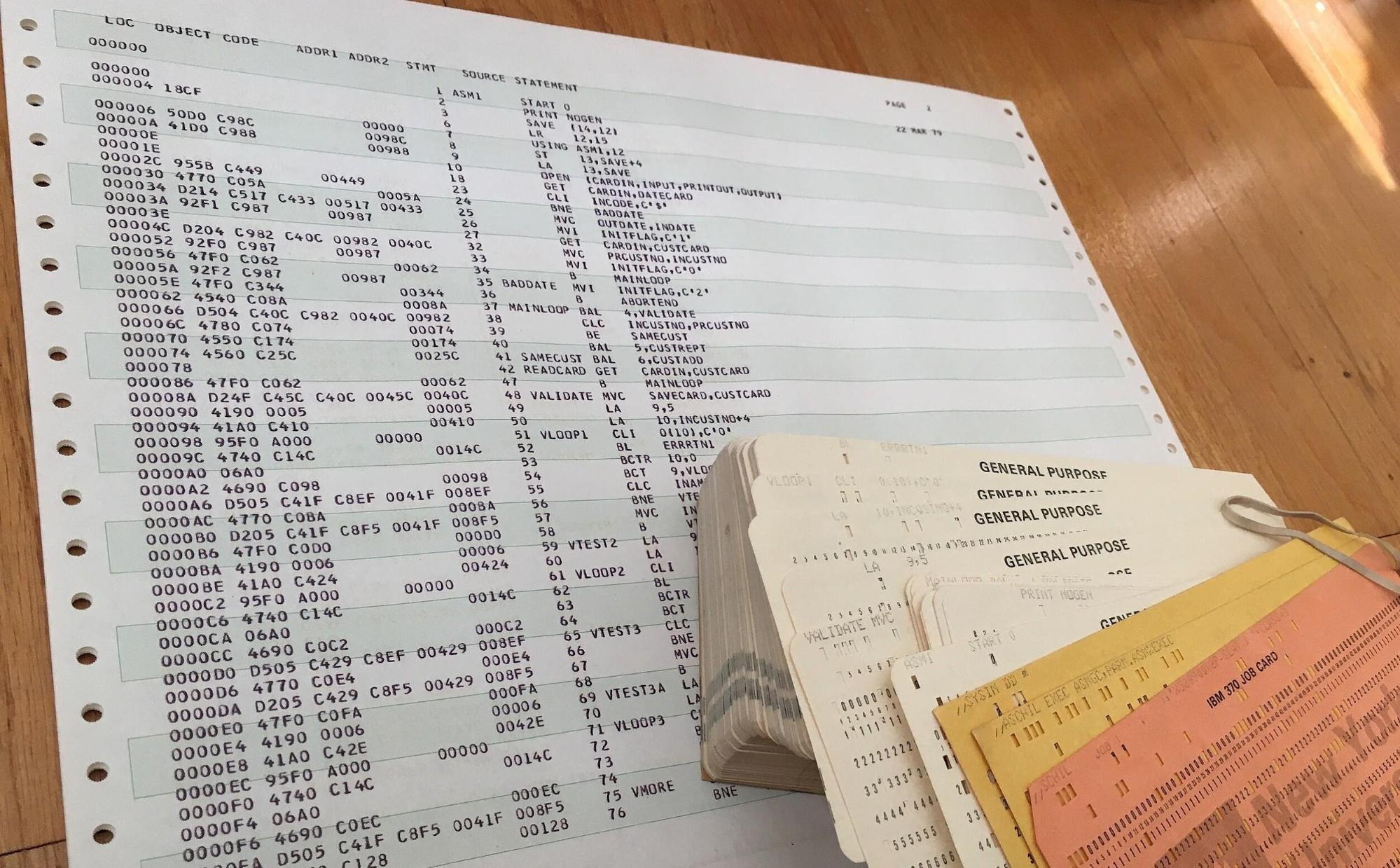
Punch cards
Babbage's Analytical Engine was designed to use punched cards for data entry and printing results. Therefore, the Ada program uses the term "variable card." Punched cards were invented by Jacquard in 1804 for weaving looms. Fabric produced on Jacquard looms became known as Jacquard.
The surname Jacquard is consonant with the surname Schickard, who lived a century earlier.
Jacquard punch card
The holes on the punched card encoded information about the fabric pattern. It could be said that the punched cards determined the program for applying the pattern to the fabric. A loom can't really be called a computer, as it lacked even the most basic calculations. For a large piece of fabric, many punched cards were used, which were then strung together into a tape. Why use cards instead of punched tape? Punched cards could be used to create new patterns by changing the set of punched cards. Another reason is that if the punched tape broke, it would have to be completely replaced, whereas with punched cards, replacing just one card was sufficient.
punch card loom
Punched cards are convenient for recording numbers and other symbols in binary form. A hole represents a one, and the absence of a hole represents a zero. The presence of a hole can be detected using mechanical probes.
In the 20th century, punched cards and punched tape were used with computers to store programs and data. They fell out of use after the invention of magnetic storage media—tape and disk.
Other display devices were more convenient for displaying calculation results: wheels with numbers drawn on them, light bulbs, and typewriters.
Reasons why punch cards were not used to output calculation results:
1) the calculation results are viewed by a person, and it is inconvenient for a person to read symbols from punched cards;
2) the calculation results are different each time and it would be necessary to use a new card or tape each time.
Morse code
In 1838, a telegraph machine using Morse code encoding appeared. Morse code is not considered a computer technology, although it uses short ("dot") and long ("dash") signals, along with spaces between them, for transmission. Each letter was encoded with 1 to 4 signals. Numbers were transmitted with 5 signals. The more frequently a letter appeared in English speech, the fewer signals were used. Morse code was never used for input and output in computer devices.
The telegraph machine and Morse code are examples of commercially successful inventions that lacked a future or theoretical (scientific) value. Among programming languages, COBOL is a dead end, although many programs were written in it in the 1960s and 1970s that are still in use today. More than 12.5 million Commodore 64 computers were sold from 1982 to 1994. This computer model is listed in the Guinness Book of World Records as the best-selling in the world. The Commodore computer line ceased to exist, and the manufacturer, Commodore International, declared bankruptcy in 1994. It was acquired by the German company Escom, which also went bankrupt a year after acquiring Commodore International, despite previously being the leading manufacturer of IBM PC-compatible computers in Europe with annual revenues of $2 billion.
Morse code
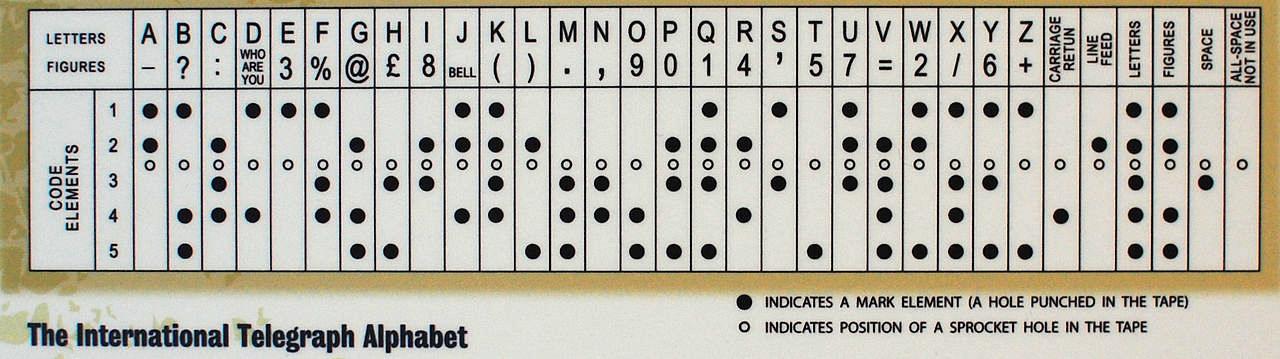
In the 1870s, Baudot created a code in which each character was transmitted using 5 bits for the telegraph, which he also invented. Baudot's code was closer to machines than to humans. Specifically, each character was transmitted using a fixed number of bits.
one of the variants of Baudot code
In 1963, the seven-bit ASCII code was introduced, and five-bit codes began to be phased out. In 1927, the historical unit of character transmission speed, the baud, was named in Baudot's honor. For binary data, a baud is the number of bits transmitted per second. For example, if a character is encoded in 8 bits, then 1 baud equals 8 bits per second.
punched tape with 5-bit code
IBM
In 1890, Hollerith designed a tabulating machine that won a competition to process U.S. census data. The tabulating machine used punched cards. In 1896, Hollerith founded the Tabulating Machine Company to manufacture tabulating machines and punched cards. These machines proved useful not only for the census but also in other sectors of the economy. In 1911, the company merged with other companies and changed its name to the Computing-Tabulating-Recording Company. In 1914, Tom Watson became its CEO, remaining with the company until his death in 1956. In 1924, the company was renamed International Business Machines Corporation (IBM).
In 1944, with IBM's participation, the Mark I relay computer was created. In 1952, the IBM 701 vacuum-tube computer was released, giving rise to the IBM 700/7000 series of computers, which became known as "mainframes." Computers in this series were produced until 1964. In 1964, the IBM System/360 series was released, significantly outperforming competitors' products and giving IBM a monopoly on the mainframe market. A mainframe is a universal, fault-tolerant computer with a large capacity of RAM and external memory.
Mainframes used FORTRAN, PL/1, Algol, COBOL, and LISP programming languages. In the 1960s, IBM held 70% of the global computer market.
In 1971, IBM created the floppy disk, which replaced punched tape and became the standard for data storage for decades.
In 1981, the company created the IBM PC, a personal computer whose architecture became the standard for the computer industry, and personal computers began to be used everywhere: for work and home purposes.
Nyquist-Shannon theorem
According to the theorem, an analog signal with a limited maximum frequency can be transmitted and reconstructed using numbers transmitted at a frequency twice the maximum frequency of the analog signal. These numbers store a measurement of the function's magnitude (amplitude). Consequently, to transmit sound with a frequency of up to 22 kHz (the maximum frequency audible to most people), a sampling frequency of 44.1 kHz (used in the first standards for digitizing sound for compact disc recording, compact-disc digital audio, or CD-DA) can be used. Sound amplitude can be measured using 16-bit numbers, which yield 2^16 = 65,536 sound levels.
The Nyquist-Shannon theorem underlies the digital transmission of analog signals over digital channels. For computing, transmitting digital signals over analog transmission channels is more relevant, and in 1948, Shannon published the article "A Mathematical Theory of Communication," where he developed Nyquist's ideas and introduced the concept of information entropy, which is a measure of information uncertainty.
Shannon's idea was that the amount of information that can be transmitted depends on the entropy (randomness of the messages in the signal source). Based on the statistical characteristics of the message source, it is possible to encode the information to achieve the maximum data rate, as determined by the theorem. At the time, this was perceived as a significant achievement, as it had previously been believed that the maximum information in the original signal that can be transmitted through a medium depended on the properties of the channel (frequency), but not on the properties of the signal. Data compression before transmission was unknown, as the computing technology and algorithms capable of compression did not yet exist.
Computer science and cybernetics
Norbert Wiener, in his 1948 book, Cybernetics: Control and Communication in the Animal and the Machine, wrote that he sent Shannon's supervisor the principles for building computers:
1) Adding and multiplying devices must be digital (Bush created an analog computer);
2) Summing and multiplying devices, which are essentially switches, should consist of vacuum tubes, not gears or electromechanical relays. This is necessary to ensure acceptable response speed;
3) The more economical binary rather than decimal number system should be used;
4) The sequence of actions must be planned by the computer so that a person does not interfere with the process of solving the problem from the moment the initial data is entered until the final results are obtained;
5) The computer must have a data storage device. This device must be able to quickly write data, store it securely until erased, read it quickly, erase it quickly, and be immediately ready to receive new data.
The principles proved accurate and predicted the future development of computers. Based on the fifth principle, the first magnetic disk drive, the IBM RAMAC, with a capacity of 5 megabytes, appeared quite quickly in 1956.
Wiener and his colleagues decided to call the theory of control and communication in machines and living organisms "cybernetics," from the Greek word for helmsman (cubernetes). They believed that ship rudders were among the first feedback devices. Wiener's colleague was Arturo Rosenblueth, a medical doctor whose last name sounded similar to Frank Rosenblatt, the creator of the perceptron.
Wiener believed that "information is information, not matter and not energy."
In 1948, the term "computer science" didn't yet exist; the term "cybernetics" was used. The term "informatik" first appeared in a German-language article in 1957. In France, the term "informatique" appeared in 1962. The term "computer science" appeared in 1959. Computer science is used in English-speaking countries, and informatics in other countries. Both words mean the same thing.
Dijkstra also believed that "computer science has no more to do with computers than astronomy has to do with telescopes."
Part 2. The emergence of computers
Boolean algebra
Any arithmetic calculations with numbers can be expressed using three logical operators : AND ( & , and, ^, conjunction), OR ( | , or, v, disjunction), and NOT ( ! , not, negation, inversion). The words conjunction, disjunction, and inversion come from Latin. The use of Latin was common in the Middle Ages. Nowadays, the use of Latin words makes understanding difficult.
The computing part of a computer can be built from a combination of three elements implementing logical operators: AND, OR, and NOT . First, numbers are converted to binary form, and then calculations are performed by applying logical operators to the bits.
In addition to these three operators, there are logical operators that can be created by combining them:
1) NAND : formed by combining NOT(x AND y) gates . First, AND is applied to the two operands, and then NOT is applied to the result. Interestingly, NAND has the property of "functional completeness," meaning that any logical function can be implemented using only NAND gates.
2) NOR: NOT(x OR y) . Returns 1 only if both operands are 0. The NOR operator is also "functionally complete." For example:
(NOT x) = (x NOR x)
(x AND y) = (x NOR x) NOR (y NOR y)
(x OR y) = (x NOR y) NOR (x NOR y)
XNOR: NOT(x XOR y).
3) ≡ , i.e. identity: (x == y) . If both operands are 0 or both operands are 1, then the operator returns 1.
4) XOR : exclusive OR. (x XOR y) returns 0 if the values of the operands are the same, and if the values of the operands are different, it returns 1. XOR is notable because (x XOR (x XOR y) = y . Using XOR, you can swap the values of two variables of the same data type without using a temporary variable.
How to replace XOR with three operators?
(x XOR y) = (x AND (NOT y) OR ((NOT x) AND y) = ((NOT x) OR (NOT y)) AND (x OR y) .
The NAND , NOR , ≡ , and XOR operators are useful because their implementation at the hardware level is more efficient than building circuits that implement the three basic operators. Flash memory technologies are called NAND flash and NOR flash because they use arrays of transistors to store bits, implementing either a NAND or NOR logic gate.
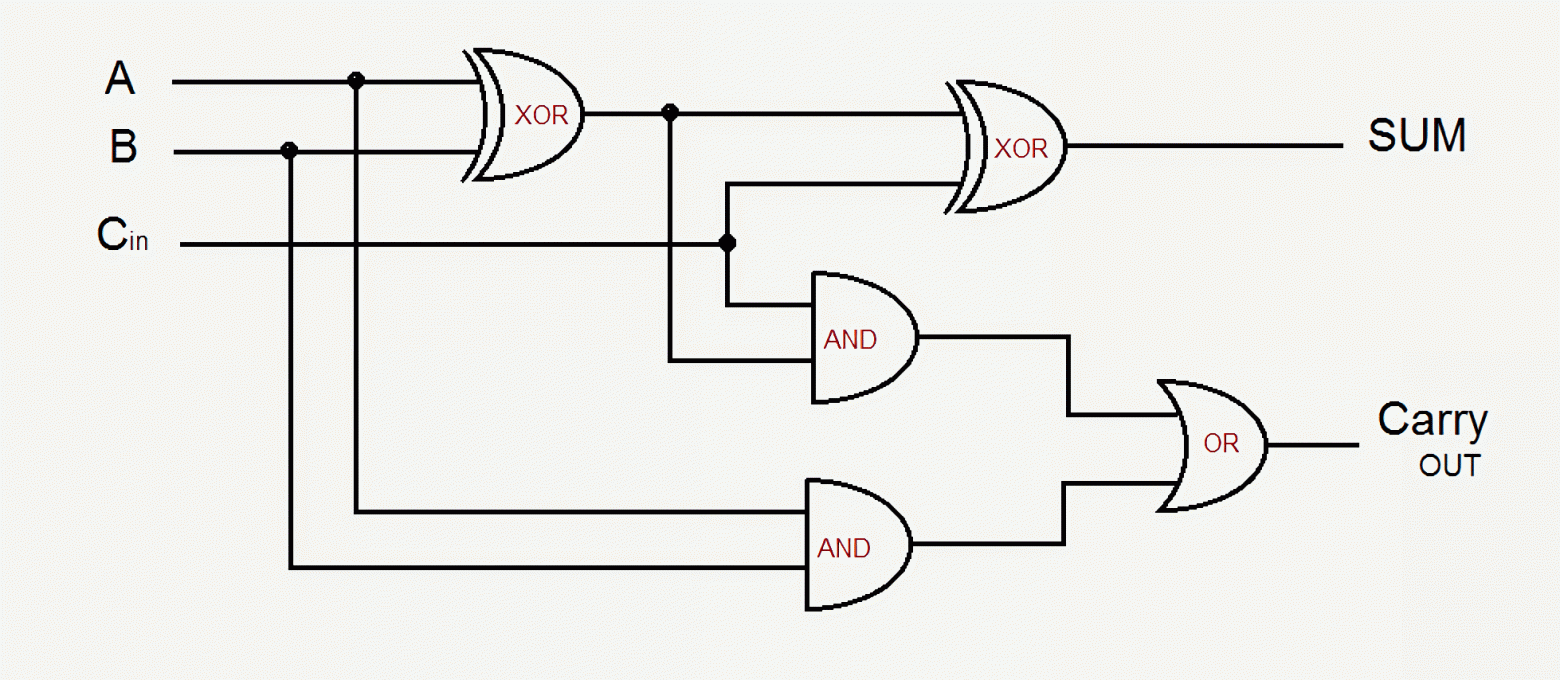
Creating circuits from logic elements
Adder circuits are used to add binary numbers. For example, suppose you need to add two binary numbers: 01 + 01 = 1 0 . The right-hand digit is the least significant (low-order digit). In decimal notation, adding these two numbers looks like this: 1 + 1 = 2 . To perform the addition, you need to perform an operation on the right-hand bits. If both of them contain 1s, the result will be zero , and the 1 should move to the digit to the left (the most significant digit). This is what adders do.
A and B are the bits whose values are to be added (summed). Cin is the signal from the lower bit. CarryOUT is the output signal for the higher bit, which will be connected to Cin of the same adder, but for the higher bit. SUM is the summation result for the bit of the current adder circuit.
In the example of addition 01 + 01 = 1 0 for the least significant digit: Cin=0 (since the digit is the least significant, there is no contact and therefore 0), A=1, B=1, SUM=0, CarryOUT=1.
For the most significant digit of addition 01 + 01 = 1 0 : Сin=1, A=0, B=0, SUM=1, CarryOUT=0.
To implement the addition of two-digit binary numbers, two adders are needed.
Modern computers work with 64-bit binary numbers, and the number of adders is quite large - also 64. Each adder contains 5 logical elements: XOR, AND, OR . Each logical element can be implemented with 6 transistors or other elements. Interestingly, an SRAM memory cell also uses 6 transistors. In total, one adder requires 5 * 6 = 30 transistors, and for summing 64-bit numbers, 30 * 64 = 1920 transistors. This is quite a lot. The number of connections between the terminals of the elements is even greater. Before the advent of integrated circuits, computers were impressive in size, and the length of wires measured in hundreds of kilometers. To be precise, it can be said that when designing without integrated circuits, the circuits were optimized, and the number of transistors (lamps, relays) to implement a logical element could be not 6, but 2-3, but resistors had to be added. Resistors generate heat, so they are usually avoided in integrated circuits.
SRAM and DRAM
Access to RAM in computers is random. The alternative to random access is sequential access, like reading from a tape. To read the contents of a tape, the tape must be rewinded, which takes time.
For RAM use:
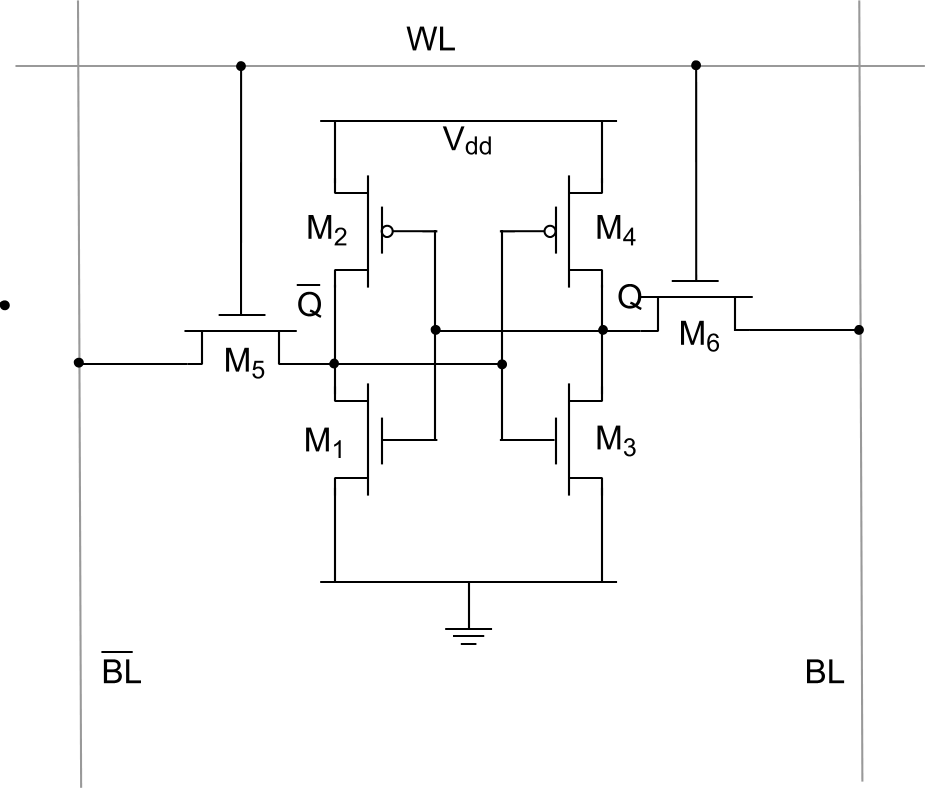
1) SRAM (static random access memory). It's called that because its contents don't need to be updated periodically. An example of an SRAM cell (storing one bit):
One bit of SRAM memory requires six transistors. Reading and writing are seamless, as no preparatory steps are required to access memory cells.
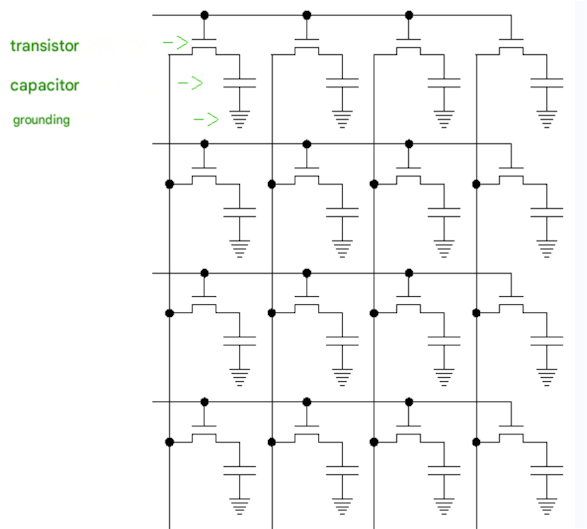
2) DRAM (dynamic random access memory) is a dynamic memory. It uses one transistor and one capacitor (a capacitor for storing electron charge), both located on a silicon chip, to store a bit. A charged capacitor stores a zero, while a charged capacitor stores a one. Due to leakage currents, the capacitor discharges over time, so it must be periodically recharged. This is where the name "dynamic" comes from, as processes that change the memory state are constantly occurring, even when the memory is not being accessed. A transistor is used to charge and discharge the capacitor and as a current amplifier to reliably determine whether the capacitor is charged or discharged. Example circuit diagram for 16 DRAM cells:
A single DRAM cell requires a transistor and a capacitor. All cells must be refreshed periodically. While one cell in a cell array (horizontally or vertically in the figure) is being read or written, other cells cannot be accessed, reducing the performance of this type of memory. Charging and discharging capacitors also takes time.
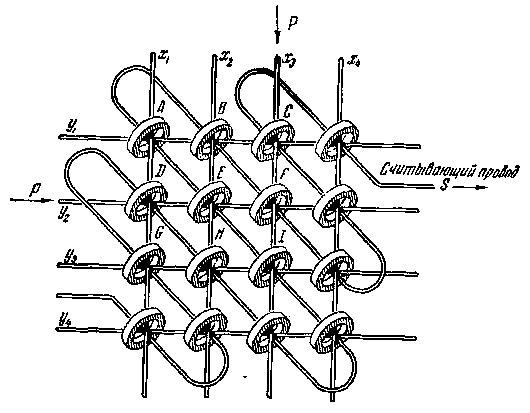
Before the advent of microchips that could be coated with layers of capacitors and transistors, memory on ferrite rings was used:
The magnetization/demagnetization rate is comparable to the charge/discharge of capacitors. The drawback of ferrite rings is that the size of each ring was at least a quarter of a millimeter, which is quite large.
The idea of using magnetic moment instead of electric charges was further developed in magnetoresistive RAM (MRAM). The performance of this memory is comparable to SRAM. The advantage of magnetic memory is that radiation does not affect the magnetic field, allowing both ferrite cores and MRAM to be used in space.
Relay computers
In 1937, Shannon was 22 years old when, in his master's thesis, "Symbolic Analysis of Relay and Switching Circuits," he described a method for implementing binary logic operators using electronic relays and switches. This laid the foundation for the design of digital circuits for future computers.
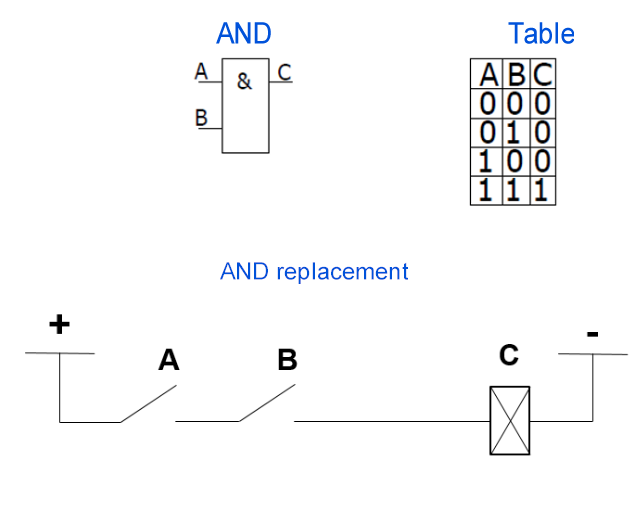
If you connect two normally open (i.e. no voltage) relays in series, you get an AND logic element - the output signal will be when voltage is applied to both relays.
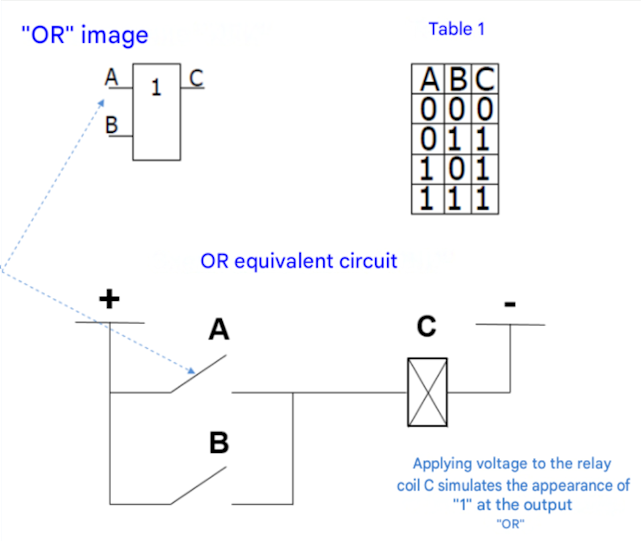
If you connect relays in parallel, you will get a logical OR element - there will be a signal at the output if at least one relay is energized.
Two normally closed relays connected in series will produce a NOR gate. Connecting normally closed relays in parallel will produce a NAND gate.
In 1944, the Mark I computer (a programmable computer) was built using electromechanical relays. It weighed 35 tons, contained approximately 755,000 components, 800 kilometers of wires, and 3 million connections. The Mark I could add 23-digit decimal numbers in 0.3 seconds, multiply in 3 seconds, and divide in 15 seconds. Trigonometric functions and logarithms took over a minute to calculate. The Mark I read and executed instructions from wide, perforated paper tape. There were no conditional jumps among the commands, and the program was a long roll of tape.
A disadvantage of relays is their slow response speed. This limited the performance of relay computers. Norbert Wiener pointed this out in his principles of computer design.
------------
The word "Mark" is a traditional designation for a serial model or version. This name is also found in the British computer "Colossus Mark 2," which was unrelated to the Mark I.
------------
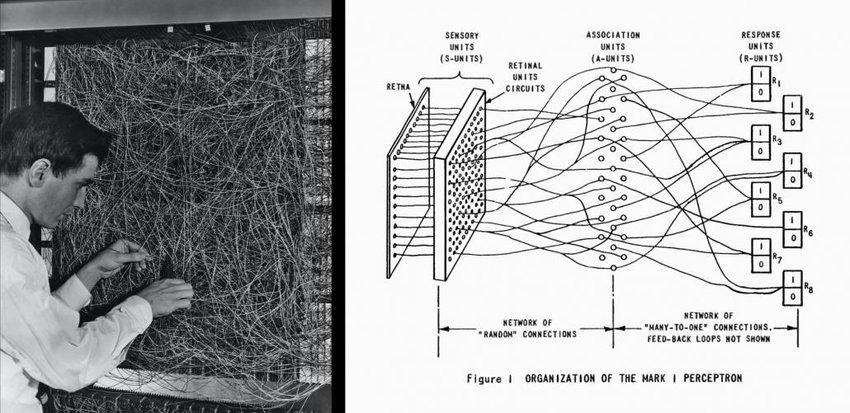
Perceptron
The name "MARK 1" also belonged to a small device created by Rosenblatt in 1958, which has been called "the first neurocomputer." The device wasn't a computer; it implemented the concept of a "perceptron" and was capable of recognizing the letters of the English alphabet with some probability. The perceptron is a model of how the brain perceives information—the way neurons in the brain were thought to work. By studying neural networks like the perceptron, Rosenblatt hoped to understand the fundamental laws of organization common to all information processing systems, including machines and the human mind. This research was not pursued at the time due to a lack of practical results. The perceptron became the first neural network model.
The brain processes data it receives from the senses, primarily vision and hearing. During this processing, a person extracts something useful—information. This data consists of the letter outlines used to recognize letters. The perceptron read the letter outlines and attempted to recognize which letter was depicted.
Speech, a complex system of signal exchange, enabled humans to develop thinking, exchange information, and store it in the memory of others or in writing. Speech enabled humans to make a qualitative leap in development compared to animals. The development of speech gave rise to languages and writing.
Large language models
A Large Language Model (LLM) is a language model consisting of a neural network with billions of parameters, self-trained (i.e., without being told: this statement is true, this is false, or a fantasy) on huge volumes of text. Large volumes of data and parameters have enabled a qualitative leap: the conclusions and inferences generated by LLM are more or less logical.
Before LLM, language models were used that used "supervised" learning. Supervised learning means that the language model is given feedback: whether it has correctly or incorrectly generated a conclusion, which allows the language model to adjust its internal parameters and make more accurate inferences. Language models are successfully used for highly specialized purposes, such as finding analogies and making predictions. For example, in face recognition and song recognition based on fragments, as in the smartphone app Shazam.
LLMs are used to extract information from text, create digests (brief descriptions), answer questions, and translate into other languages.
Generative artificial intelligence uses LLM to generate text and images in response to prompts from the person who sets the task for it.
Generative artificial intelligence can use text, which consists of words; program code; images to generate pictures and videos; and molecular diagrams and amino acid sequences to generate molecules and descriptions of the properties they may have.
Vacuum tube computers
The response speed of lamps is much higher than that of relays, and lamps began to be used instead of relays.
In 1945, the Electronic Numerical Integrator And Computer (ENIAC) was completed – a vacuum tube-based computer that operated successfully until 1965. It used 17,500 vacuum tubes, 7,000 diodes, and 1,500 relays.
UNIVAC I vacuum-tube computers were produced from 1951 to 1958. They contained 5,200 vacuum tubes, weighed 13 tons, and occupied a floor space of 4 x 2.5 meters. An electric typewriter served as the output device, and magnetic tape served as the external data storage.
Vacuum tube computers are considered the first generation of computers.
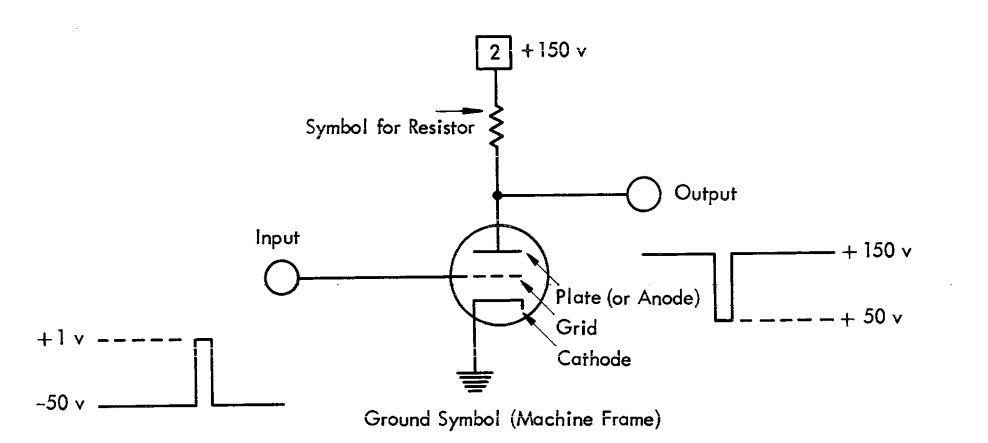
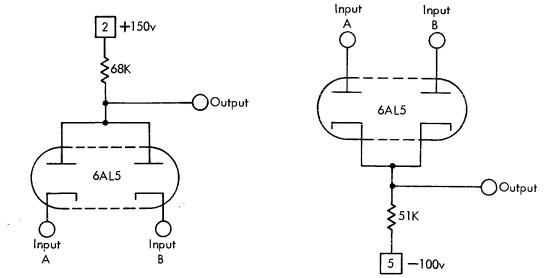
An example of implementing NOT logic on a vacuum tube triode:
When a voltage of +1v appears on the Input contact, the triode “opens” - electrons begin to move from the cathode to the anode and the output voltage drops from 150 volts to 50 volts.
The disadvantages of lamps included high voltage, operating temperatures, the need for adjustment (tuning), and frequent breakdowns. Tuning consisted of checking that the lamps switched within specified voltage ranges. Failures occurred frequently, even more frequently than in relay machines.
An example of the implementation of elements on vacuum diodes:
on the left is the implementation of AND logic, on the right is the implementation of OR logic
Two diodes are combined in a single vacuum tube. The difference between the logic elements is in the resistor values and voltage. For AND logic, both diodes must begin to conduct current only when voltage is applied to inputs A and B. Vacuum tube diodes begin to conduct current intermittently when the voltage difference exceeds the threshold beyond which electrons can move in a vacuum from the cathode to the anode.
For AND logic, the resistor value and voltage are selected so that to open any of the diodes, voltage must appear at both inputs; the appearance of voltage at one of the inputs is not enough.
For OR logic, the resistance value and voltage difference are smaller. To turn on either diode, simply applying voltage to one of them is sufficient.
Although vacuum tubes can operate at high frequencies, they require high currents and voltages. Using vacuum tubes for switching causes current surges in the power supply circuits. Increasing the switching frequency increases the number of errors and limits the performance of vacuum tube computers.
Transistor
In 1947, the transistor was created . Its operating logic is similar to that of a vacuum tube triode, but its size, voltage, and temperature are much lower. Semiconductor elements also don't wear out and are not susceptible to mechanical stress. After transistors entered industrial production, they began to be used in computers instead of vacuum tubes. Like relays and vacuum tubes, transistors are used in computing as switches:
1) the transistor is “open” (“on”, passes current) - corresponds to one;
2) the transistor is "closed" (does not pass current) - corresponds to zero.
Transistors don't handle large currents in switching mode, and their voltages are also small (a few volts), unlike vacuum tubes, which operate at around a hundred volts. The transistors' high-voltage level is 3.3-5 volts, and the low-voltage level is 0-1.6 volts. The supply voltage of the microcircuits varies, but ranges from 3-15 volts.
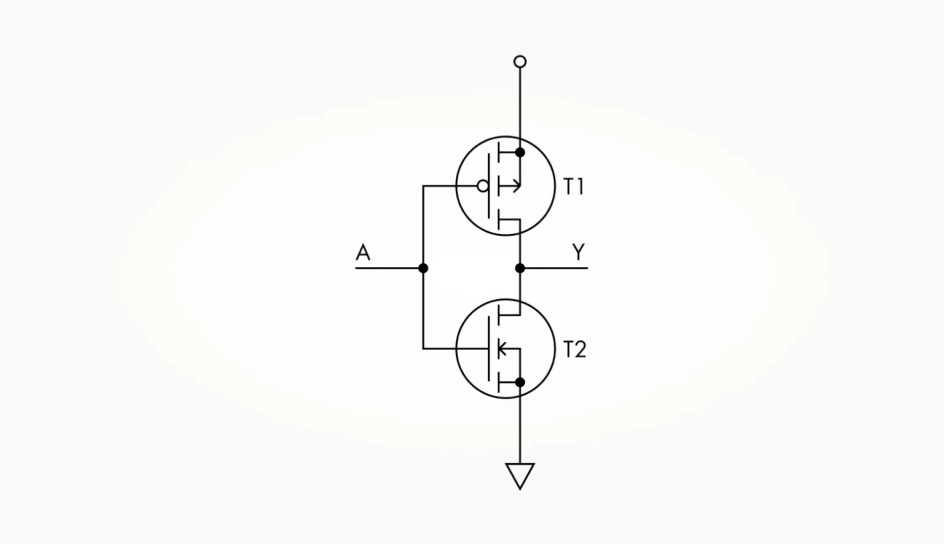
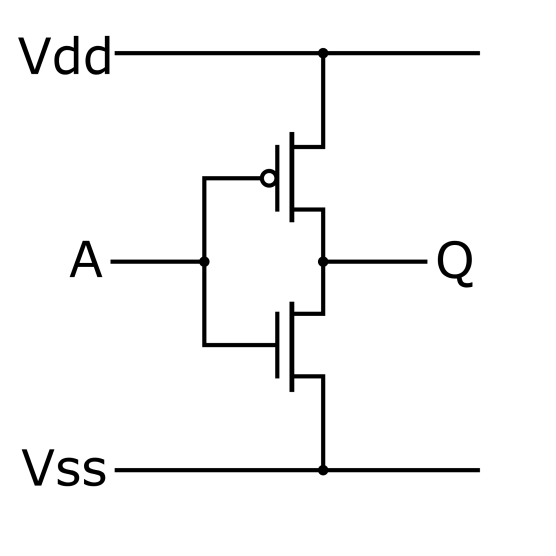
Transistors come in two types: n -channel and p- channel. The same voltage opens an n- channel transistor and closes a p -channel transistor, meaning they complement each other. In the diagram, n- channel and p- channel transistors are distinguished by the direction of the arrows and/or the presence of a small circle near the gate.
A large circle in a schematic indicates the presence of a transistor package. Schematics use a variety of symbols. For example, for circuits with field-effect transistors, the supply voltage is designated as Vdd (drain, where electrons flow, positive) and Vss (source, negative).
It's commonly believed that current flows from positive to negative, which is confusing. This is because electrons were discovered later than electricity, and they weren't known to be charge carriers. Therefore, the current flowed from positive to negative, as during galvanization, metal atoms flow from the positive terminal and settle on the negative terminal.
implementation of a NOR logic element using polar transistors
Computers that use transistors are considered the second generation of computers, while those that use microchips are considered the third generation.
The BESM-6 computer belongs to the second generation. A total of 355 machines were produced between 1968 and 1987.
The third generation includes the IBM System/360 series. This series began production in 1965. The 360 was succeeded by the 370 series (announced in 1970), then the 390 series, and the System z. An example of a circuit board from the IBM 7090 transistor computer:
The round parts are transistors. The striped parts are resistors. The color stripes encode the resistor's resistance value.
IBM 7090 computer at Stanford University:
Microchips
As the number of transistors, resistors, and capacitors increases, computer reliability decreases, and troubleshooting time increases. This is because there are more contacts, which can oxidize and stop conducting current.
Since the power dissipation when using transistors as switches ("gates") to implement logic elements is low, transistors can be made miniature. Transistors can be combined into a single package (microcircuit). This idea emerged in 1952, and mass production of microcircuits was launched in 1959.
Digital technology uses microchips made using CMOS (complementary metal-oxide-semiconductor) technology. CMOS uses insulated-gate field-effect transistors (FETs). FETs are used because they have low current consumption, and energy is expended primarily during switching. CMOS microchips appeared in 1968.
An alternative to CMOS is TTL (Transistor-Transistor Logic) microcircuits using bipolar transistors and resistors. CMOS operates at a much higher speed and has a much higher packaging density than TTL.
Silicon Valley
Semiconductors are chemical elements and chemical compounds. The elements include germanium, silicon, carbon, boron, tin, tellurium, and selenium. Germanium and silicon have a diamond-like crystal lattice.
The first transistors used germanium crystals, and even a germanium-based integrated circuit was invented at Texas Instruments, but silicon turned out to be the most convenient for creating microcircuits, since its dioxide is an excellent dielectric and silicon is mechanically strong over a wider temperature range than germanium.
Compounds of chemical elements such as gallium arsenide, silicon carbide, and gallium nitride (GaN) are also suitable for creating semiconductor elements. Gallium nitride has gained popularity relatively recently, finding its way into electronic power supply circuits. Power supply circuits have become simpler, offering greater power while offering a smaller footprint.
In 1959, Fairchild Semiconductor developed a "planar" (flat, surface) technology for creating microchips. Conductive and non-conductive (dielectric) layers are deposited on a flat silicon crystal wafer. Until 1965, the company was a leader in the semiconductor industry, but due to poor management, engineers began leaving. The engineers founded numerous technology companies in the San Francisco Bay Area, California. The area where these new companies were located became known as "Silicon Valley." Two engineers, Robert Noyce and Gordon Moore, left Fairchild Semiconductor in 1968 to found Intel.
Harvard Computer Architecture
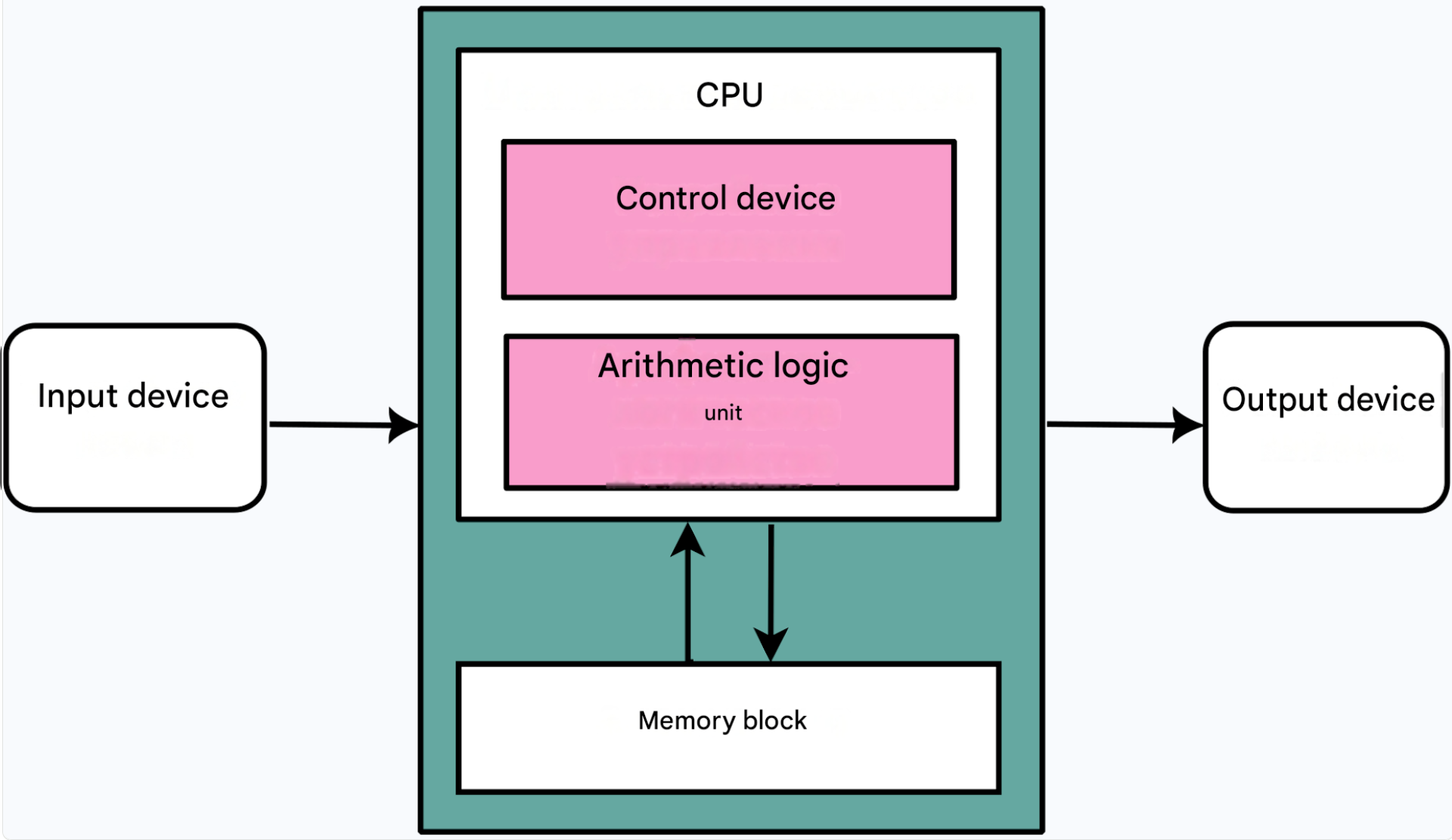
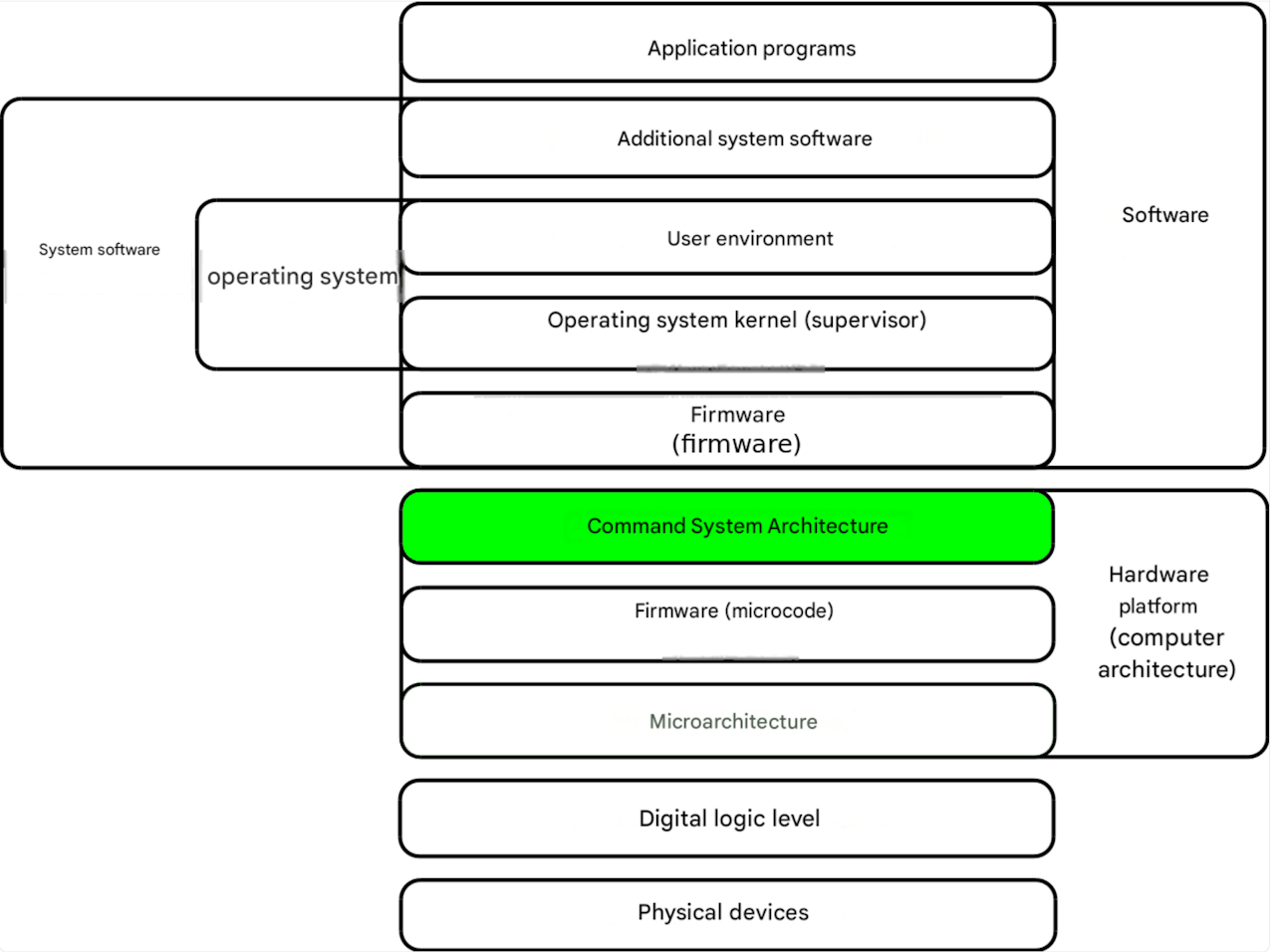
Computer architecture is a model of a computer consisting of its parts, a description of how these parts interact with each other and the outside world, and the principles of design and development . Computer architecture includes a description of formats, instruction types, parameters, and enhancements. The term "computer architecture" was coined in 1959 to replace the term "machine organization."
Since yin-yang, zero and one, and transistors with n and p channels appeared, two architectures were created in the history of computers: Harvard and Princeton.
The Mark I computer used the "Harvard" architecture. In the Harvard architecture:
1) The memory where the program code (command sequences) is stored and the memory where the data processed by this code is stored are physically separated. Segregation and discrimination: data cannot become code, and code cannot generate new code;
2) The bus through which the code is transferred for execution and the data bus are physically separated from each other. The figure shows that the code (instructions) and data enter the processor (specifically, its part: the control unit) via different buses (channels):
The advantage of the Harvard architecture is that it has two buses: one for data and one for program code. Data and code can be transferred twice as fast as with a single bus.
However, separating code from the data it processes complicates programming. A program also cannot create program code and transfer control to it. For example, in the Harvard architecture, it is impossible to launch an operating system, create a program within the operating system, compile the created program, and execute it.
In Harvard architecture, the separation of data and program code allows for better "security" - data cannot become code, but the maximum "security" is the absence of a computer: "no computer - no problem."
The Mark I computer used punched tape for instructions and electromechanical "registers" for data processing. A register is a memory unit for storing a number.
Von Neumann architecture
In the von Neumann ("Princeton") architecture, programs and data are stored together in shared memory. This allows the same operations to be performed on instructions as on data, such as creating program code and transferring control to it.
The bottleneck in the von Neumann architecture is the memory access channel (bus). To speed things up, caches are used, which complicates processor design. This drawback is offset by the ease of program creation and functionality. Modern processors use the von Neumann architecture.
Harvard architecture has found its way into controllers (processors specialized for a single task) that process audio data (Digital Sound Processors, DSPs ), where it's crucial to avoid latency, ensure the audio doesn't drift in time, and avoid the need for complex solutions to synchronize audio data with time. Audio data flows at a uniform speed along a data channel, while commands flow along a different channel from the portion of the controller's memory where the audio processing microcode is loaded.
Harvard architecture is also used for L1 cache memory in modern processors. These processors have separate instruction and data caches. To work with the L1 cache, the processor designer typically creates "microcode"—control software that can be modified if necessary. This becomes necessary when:
1) errors in the microcode;
2) instability of the processor under load;
3) high heat generation;
4) that it is possible to improve the logic of the microcode or add new commands.
If the program could not be changed when an error was detected, then the defective processors would have to be replaced with new ones.
----------
In 1994, a bug was discovered in Intel Pentium processors. When dividing two floating-point numbers, the result was sometimes incorrect. The processor command was called FDIV (float divide), so the bug was dubbed the "Pentium FDIV bug." The processor's lookup table, used for the division operation, contained an erroneous value. The table couldn't be replaced because the processor didn't use microcode. Intel discovered the problem after the processors were already being sold and concealed it, believing the issue was only significant for scientific computing, while programs used by ordinary users rarely divided floating-point numbers. Customers wishing to replace the processor had to contact the company and prove that the bug was significant to them. The desire to conceal the problem and the lack of respect for customers caused dissatisfaction and negatively impacted Intel's reputation. Intel corrected the issue and announced that it would freely exchange processors. Andy Grove, the CEO and co-founder of Intel, publicly apologized for his misbehavior. The mistake cost Intel $475 million, more than half of its profit in the fourth quarter of 1994.
In 2022, contaminated copper was used in the production of the Raptore Lake processor. Copper holes in the contact pads beneath the processor die oxidized, causing the processor to malfunction and eventually fail. Intel discovered the issue but did not disclose it to the public, even as more and more processor users began experiencing the problem. In its initial response to the problem on April 29, 2024, Intel blamed microcode that allegedly allowed for increased processor voltage and shifted responsibility to motherboard manufacturers that allowed for increased processor voltage. On July 22, 2024, Intel admitted to a manufacturing defect in its processors, but the statement was still convoluted (and misleading): "We can confirm that a manufacturing oxidation issue affected some early 13th Gen Intel Core desktop processors. However, the issue was addressed and resolved through manufacturing improvements in 2023. We have also investigated reports of instability involving 13th Gen Intel Core desktop processors, and our analysis indicates that only a small number of instability reports may be related to the manufacturing issue. We are shipping a microcode fix for the instability issue that addresses the overvoltage impact, which is a key element of the instability issue." Within a few days, Intel shares lost a third of their value.
----------
Cache memory is used to accelerate the processing of data from RAM (main memory). Its capacity is small, and its operating frequency matches the processor's clock rate. Data from RAM is automatically loaded into it by firmware code. RAM is orders of magnitude (tens or even hundreds of times) slower than cache memory. Six transistors are used to store a bit, making cache memory more expensive and occupying more space than main memory. Main memory uses a capacitor and a transistor to store one bit.
Microcode for DSPs and processors is flashed into flash memory (persistent storage memory) that is physically separated from the processor's main memory.
In biology, DNA is used for both data storage and coding. It's fair to say that cells employ Princeton architecture rather than Harvard. Von Neumann developed the concept of a cellular automaton—a self-reproducing machine.
Machine word
A machine word is a fixed-size chunk of data processed as a single unit by the hardware processor commands. For example, the command to add a number in memory cell a to a number in cell b is: ADD a, b . Computers process numbers using binary representation, so computers have a simple alphabet: only two "machine letters": 0 and 1.
By analogy with human language, a letter is something that a person perceives as indivisible (atomic, discrete). For example, the letter "A" cannot be divided into parts. In human languages, word length is arbitrary.
---------------
In 1948, Shannon first used the word bit (binary digit) to denote the smallest unit of information in his paper "A Mathematical Theory of Communication".
A bit is a symbol that can take one of two values: yes or no, true or false, on or off. In the binary number system, a bit is 1 (one) or 0 (zero).
Shannon uses the word "information" to mean data. In human speech, information, or knowledge, is something meaningful. For example, the number 299792458, is data. The number itself has no meaning, just a collection of digits. Information is the fact that 299792458 is the speed of light in a vacuum, measured in meters per second. Information is what a person extracts from data.
--------------
At first, computers were used only to process integers and real (floating-point) numbers and were called computing machines. Real numbers were used for scientific calculations: logarithms, projectile trajectory calculations, and nuclear physics calculations. Later, computers found applications in economics and began to be used to store and process not only numbers but also letters. The English alphabet has 26 letters. In written language, in addition to letters, decimal digits (there are ten of them, 0123456789 ) and punctuation marks are used, for example: " !?,.() ".
Let's calculate how many characters we get: 26 letters plus 10 numbers plus 10-20 punctuation marks. That's a total of 46-56 characters. 6 bits are enough to store 56 characters. Therefore, at the dawn of the computer era (in the 1950s and 1960s), the length of a "machine word" was 6 bits. 6-bit encoding was used because 6 bits were enough to represent all the digits and letters of the English alphabet: the combination of bits allowed for the encoding of 32 characters in a single case, 10 numbers, and punctuation marks.
Example: two bits can encode four characters: 00, 01, 10, 11. Three bits can encode eight characters: 000, 001, 010, 011, 100, 101, 110, 111. Continuing, we find that the number of characters that can be encoded by the number of bytes is equal to two raised to the power of that number. In the example given, two to the power of two equals four, two to the power of three (2*2*2) equals eight.
The Intel 4004 microprocessor, released in 1971, had a 4-bit word size, but this microprocessor was designed for calculators and number crunching.
Later, only powers of eight began to be used for the "machine word" length: 8, 16, 32, and 64 bits. This is because for a chip on a crystal, it makes no difference whether it has 6 or 8 conductor lines; it only slightly increases the area and heat dissipation of the microprocessor die. The difference in the number of bits in a machine word significantly affects program writing. With the advent of microprocessors, the labor intensity of writing programs began to play a greater role than the reduced cost of hardware. To simplify matters, memory addressing was also standardized, becoming 8, 16, 32, and 64-bit. Porting programs to new processor versions is simple if the machine word length doubles. With the advent of 16- and 32-bit x86 processors, programs written for 8-bit processors didn't even need to be recompiled.
Eight bits were called a byte. Powers of eight—8, 16, 32, and 64 bits—are reflected in programming languages. Many programming languages have data types for integers: byte (8 bits), short (16 bits), integer (32 bits), and long (64 bits).
--------------
The word "byte" was first used in June 1956 during the design of the IBM 7030 transistor computer to denote a portion of bits transmitted simultaneously along wires. The number of wires varied from one to six. Later in the same project, the byte was expanded to eight bits. The word "byte" (b y te) was chosen as a corruption of the word b i te (translated as "portion"), pronounced the same way. The replacement of the letter " i " with " y " was necessary to avoid confusion with the word b i t.
Byte-based memory addressing was first used in the IBM System/360 line of computers. Earlier computers could only address entire machine words, which consisted of 36 (IBM 701), 18 (PDP-1), or 48 (CDC 1604) bits, making it difficult to process text data.
--------------
An example of a von Neumann architecture computer in operation
In 1953, one of the first computers, the Strela, was created. It used a simple and straightforward "three-address instruction set" with a fixed word length. This made it relatively easy to write machine code and learn how to write it.
The Strela's memory consisted of 2048 cells, each of which stored 43 bits.
Each memory cell, according to the von Neumann architecture, stored either a 43-bit number or a 43-bit instruction. That is, a machine word was 43 bits in size.
The command consisted of five parts. An example of a command written in decimal form:
2045 2046 2047 0 01
This command means: add the number from cell number 2045 (command code 01 ) to the number from cell number 2046 and place the result in cell number 2047. Each command in this machine has three operands.
12 bits were used to store the addresses of memory cells: the number of cells 2028 is equal to two to the power of eleven, another bit was used in reserve so that the memory could be expanded to 4096 cells.
The three cell addresses used in each command occupied 12 x 3 = 36 bits. This left 6 bits for commands and a "check digit." The "check digit" occupied one bit and took the value 0 or 1. The "check digit" was used for program debugging. To debug, the operator would flip a switch on the Strela computer panel, and program execution would pause after executing program commands whose "check digit" was equal to 1. The operator would glance at the Strela panel, which consisted of lights, and could use them to view the contents of memory cells. The operator could then continue program execution until the next stop.
Six bits were allocated for the command number out of 43 bits. The arrow used 44 commands. Six bits allow for up to 64 commands (two to the sixth power).
Arrow had command # 20 for a conditional branch (analogous to the GOTO or jump operator). Example:
0031 0032 0000 0 20
The Strela's arithmetic unit generated a signal (with two states: 0 or 1). This signal took the value 1 if the result of the arithmetic operation was negative. Command # 20 checked this signal, which was left over from the previous command. If it was zero, it transferred control to the first command address (in the example, # 0031 ); if it was one, it transferred control to the second (# 0032 ). The third address was not used in command # 20 .
A program consisting of numbered lines of five numbers of the form:
1) 2045 2046 2047 0 01
2) 0031 0032 0000 0 20
This is an example of a program in machine codes.
Example of the Strela computer remote control:
Data and programs were entered into the Strela from punched cards, output to punched cards, or printed on paper tape. One punched card could hold twelve 43-bit numbers. One punched card could hold 12 machine words. The Strela's operating speed was 2000 instructions per second.
In computers that use a division between registers and RAM, instructions accept one or two operands, rather than three as in the Strela. With fewer operands, programming in machine code is more difficult. The disadvantage of programming in machine code is that if you need to insert an instruction in the middle of a program, the addresses of all instructions below it will change (shift). You'll have to recheck all the jump instructions that pointed to the old addresses and change them to the new ones. This problem doesn't exist with assemblers: during the translation from assembly code to machine code, memory addresses and registers are assigned automatically.
Assembler
An assembler is a translator (converter) of a program from assembly language text to machine code. Instead of machine code, assemblers use human-readable notations for commands (for example, add instead of 01 , jump instead of 20 ) and the operations to be performed. Assemblers can use variable names and label lines of code. Assemblers allow you to use variable names instead of specifying a memory cell address, and labels instead of specifying the memory cell containing the command. During translation, labels are replaced with memory cell addresses, which are automatically assigned based on the number of available cells.
Assemblers made writing programs easier than writing programs in machine code.
Retro computer emulators
The website http://tpmail.ru/dstef/m20/index_ru.html contains an emulator (a program simulating the operation) of the 1959 M-20 computer with a three-address instruction set, like the Strela. The M-20 has a 39-bit machine word, including a 6-bit operation code and three 11-bit memory pointers, allowing it to address 2048 memory cells. This emulator runs on Windows.
The website http://www.besm6.org contains documentation and an emulator (a program that simulates the operation) of the BESM-6 computer (the computer was created in 1967):
The BESM-6 used single-address register commands, and coding was more complex. Three-address commands are simpler and better suited for training. The emulator's advantages include a dashboard displaying the values in the Write Buffer Registers (BRZ), the DISPAK operating system with program sets, and assemblers (in Soviet computer documentation, assemblers are referred to as "autocode").
Three-address commands are used in the virtual "Educational three-address machine UM-3" for studying programming in the first year of the Faculty of Computational Mathematics and Cybernetics of Moscow State University: http://cmcmsu.info/1course/um3.command.set.htm
The emulator pages contain instructions on how to download, compile, and run the emulator, but there are no instructions on what to do next. For example, there are no instructions on how to run a simple game or how to write and run a simple program after playing. There are also technical flaws. For example, the BESM-6 emulator uses a keyboard layout that differs from that of modern keyboards, making it difficult to type commands. In the UM-3, the mnemonic (abbreviated) names of the commands SLC, VCHC, and UCCH are difficult to understand. The abbreviations SUM, SUB, and MUL would be clearer and more similar to the names of commands and functions in modern programming languages.
The Computer Simulation and History project's website http://simh.trailing-edge.com/ offers emulators of other computers, including DEC PDP and VAX. The downside is that documentation for the computers collected on the site is scant and in English, making the emulators inconvenient for learning.
Ergonomics
In 1940, at an exhibition in New York, the "Nimatron" electronic relay gaming computer was demonstrated. It wasn't a general-purpose computer; the Nimatron could run a single program—a game of "nim."
Although it was the first gaming computer in history, neither the game nor the computer itself had any impact on the development of electronic games or computers. What was noteworthy was that, for the first time in history, a computer was intentionally slowed down. The computer calculated its moves in a fraction of a second, which frustrated players who carefully considered each move. To prevent players from feeling inferior, a slowdown was added to the computer's move results.
------------
Ergonomics studies how to adapt job responsibilities, workstations, work objects, and computer programs for safe and effective use, based on human physical and mental characteristics. This is accomplished by examining human actions during work, the speed of learning new technology, the expenditure of mental, psychological, and physical energy, and productivity and work intensity.
-----------
If the curriculum you are studying a subject with is not clear, it may be that the curriculum is not ergonomic, that is, it is not easy to understand.
The Nimatron was developed by Edward Condom, who became director of the National Institute of Standards and Technology (NIST) in 1945 and president of the American Physical Society in 1946.
The second gaming computer in history was the Nimrod, created in 1951 based on a clone of the Mark I computer. It was used at industrial trade shows to promote computers. It used 350 vacuum tubes for calculations, 130 spare tubes, 120 relays, and several germanium diodes. It consumed 6 kilowatts of power.
--------------
Nimrod is the name of a king in ancient Babylon who wanted to burn Abraham, but Abraham did not burn, which ultimately upset Nimrod.
If a microprocessor is overloaded with calculations, it will generate a lot of heat and may even burn out. To prevent this, the processor's processing speed (receiving, calculating, and returning) is slowed down. The Nimatron computer slowed down data return. If a person is overloaded with tasks, they will burn out. To take a break, people take a vacation. Heat can be removed from the processor, using cooling (air or liquid). To reduce the information content in human speech and writing, one can "water down"—dilute information with unnecessary words. This paragraph is an example of "watering down," since it, unlike the previous text, contains almost no information. However, "watering down" can be useful: the phrase "slowing down was added" gives a useful idea: if you are tired of reading a text, you can pause and take your time.
--------------
Microprocessors
On November 15, 1971, the Intel 4004 microprocessor was released.
----------
A microprocessor is a microcircuit on a silicon crystal that contains everything related to the processor logic: a computing and logical device, a control device, registers, a timer, memory management devices, and also the ability to execute arbitrary programs on it.
----------
The Intel 4004 microprocessor used Harvard architecture, which meant separate storage of programs and data, making it unsuitable for programming. The microprocessor's registers and internal data bus were 4-bit wide. The microprocessor was developed for the Japanese company Nippon Calculating Machine for their calculator and consisted of 2,300 transistors.
On April 1, 1972, the Intel 8008 processor was released. It featured the von Neumann architecture (with shared memory for code and data), 3098 transistors, an 8-bit bus, and 14-bit memory addressing, allowing it to access 16 kilobytes of memory. The 8008 processor is not an evolution of the 4004 processor; they have different architectures and instruction sets.
--------------
In July 1974, Radio-Electronics magazine published an article advertising a computer with an Intel 8008 processor, dubbed the "Mark-8 Personal Minicomputer ." The minicomputer's developer contacted Popular Electronic magazine, but they declined to publish the article. The article offered a schematic for the computer for $5 and circuit boards for $50. The computer's components were suggested for sourcing and purchasing. The personal minicomputer was not a success. Traditionally, the inventors do not profit, but most likely the main reason was that amateur radio enthusiasts did not want to waste time searching for components for assembly. People enjoy tinkering with and creating things themselves, but only if they are not too complex.
The cover of Radio-Electronics magazine for July 1974
--------------
In 1974, the Intel 8080A microprocessor was released. It featured 4,758 transistors, 16 data transfer instructions, 31 data processing instructions, 28 branch instructions, and 5 processor control instructions. A 16-bit memory bus was used, allowing the processor to access 64 KB of memory. It utilized the von Neumann architecture, meaning memory was not divided into program and data memory. The processor retailed for $360. The Intel 8080A was a significantly improved version of the Intel 8008, offering a significantly expanded instruction set.
The Intel 8080A processor was used in the Altair 8800 microcomputer, which appeared in 1975. Popular Electronics magazine published an article about the Altair 8800. The computer was sold as a kit for $439 or assembled for $621.
The cover of Popular Electronics magazine for January 1975
Demand for the Altair 8800 exceeded expectations. Several thousand kits were sold in the first month of sales. Remarkably, the magazine's subscribers—radio enthusiasts—preferred the kit itself, meaning they were aiming to build the computer themselves. The computer lacked a keyboard and display, making it difficult to use for practical tasks.
The computer's popularity was boosted by a radio amateur magazine, a favorable price compared to the retail price of the processor, the successful S-100 system bus, and the open architecture. Radio amateurs created expansion boards that transformed it into a fully-fledged computer with peripherals. Radio amateurs pursued their favorite pastime—designing and customizing it. But most importantly, programs began to be written for this computer. Paul Allen and Bill Gates wrote a BASIC interpreter for the Altair 8800.
-----------------
In the USSR, a clone of the Intel 8080A processor was produced under the name KR580VM80A.
In 1986, the magazine "Radio" published schematics for assembling a "Radio 86RK" microcomputer. After some time, kits for assembling the Radio-86RK computer began to be released. These kits were called Elektronika KR-01...KR-04 and sold for 395 rubles. In 1987, a clone of the "Radio-86RK" called "Mikrosha" was released; it sold for 500 rubles:
Previously, the "Radio" magazine (in 1982-1983) published schematics for the "Micro-80" computer, but it contained approximately 200 components. As with the Mark-8 computer, the components were required to be purchased independently, so the "Micro-80" never gained popularity.
-----------------
IBM PC
On June 8, 1978, the Intel 8086 microprocessor, Intel's first 16-bit microprocessor, was released. Its instruction set became the basis for the x86 architecture. The instruction set was incompatible with the Intel 8080 instruction set, and assembly language programs had to be rewritten to run on the new processor.
The processor had 98 instructions: 19 data transfer instructions, 38 data processing instructions, 24 jump instructions, and 17 processor control instructions. Modern processors retain the ability to execute all of these instructions. The processor could address 1 MB of RAM using a 20-bit address bus. The data bus was 16-bit. The initial price of the processor was $360. A similar processor, the Intel 8088, was released, which cost much less – $125.
IBM decided to use the 8088 processor in its new line of IBM PC (Personal Computer) computers, released in August 1981.
IBM PC led to success:
1) modularity - the computer consisted of easily replaceable modules;
2) open architecture - the computer's designs were not kept secret and were sold for $49, allowing third-party companies to produce peripherals and clones
3) the presence of BIOS—a program providing a standard software interface for accessing devices located on the motherboard, which simplified software development. Starting in 1984, BIOSes from third-party manufacturers began to appear, including Phoenix, American Megatrends, and Award Software.
The open architecture of the IBM PC made it the standard for personal computers, displacing its competitors. In 1987, IBM attempted to displace third-party manufacturers by releasing a series of personal computers called the "PS/2" with a closed architecture and an MCA bus. However, it was unable to compete and ultimately ceased producing personal computers itself. The keyboard and mouse connector (hardware "port") migrated from the PS/2 architecture to the IBM PC architecture, becoming known as the PS/2 port, as well as the reduced-size 3-inch floppy disks, which were replaced by 5-inch ones.
On February 1, 1982, the 80286 processor was released, which was fully command-compatible with the 8086 processor. The memory address bus was increased to 24 bits, so the processor could work with 16 MB of RAM.
In 1985, the 80386 processor, the first 32-bit processor in the x86 processor family, was released. Its registers were expanded to 32 bits (making the word size 32 bits), and memory addressing was simplified. The processor could address 4 GB of RAM.
In 1989, the 80486 processor was released, and in 1993, the processor received its own name: Pentium.
Little Endian and Big Endian
Data is measured and stored in bytes. One byte consists of 8 bits and can encode 256 (two to the power of eight) distinct values, which is not much. In the real world, larger numbers are used. For numbers outside the range of 0 to 255, multiple bytes are required.
Numbers are stored in computer memory. Memory can be thought of as an ordered set of bytes, from first to last. For example, the decimal number 255 can be written in binary as 11111111 . The decimal number 256 requires two bytes to store and can be written in binary in two ways:
00000001 00000000 - from the most significant byte to the least significant byte (big-endian, BE), the most significant byte has a lower address.
00000000 00000001 - from the least significant byte to the most significant byte (little-endian, LE)
Bits are traditionally written from most significant to least significant. There's no ambiguity with the order of bits, but the order of byte writing and transmission has historically been controversial.
--------------
The terms big-endian and little-endian are taken from Jonathan Swift's novel Gulliver's Travels. In the novel, the Lilliputians are divided into two camps: those who prefer to break an egg from the sharp end (little end) or from the blunt end (big end).
The creators of these terms understood the irony of the existence of two options, but alternatives constantly emerge—there's always someone with an alternative view, even if it's clear the alternative is meaningless. Meaninglessness can be proven, but not convinced, because proven meaninglessness becomes a principle.
An alternative view is that alternatives are useful because they make life less boring - people can choose.
--------------
Although big-endian notation seems more natural and understandable, little-endian has an advantage when processing data: with little-endian notation, the number's address (the pointer to the first byte of the number) is independent of the data length. For example, the number 127 is stored in 16-bit format and occupies two bytes:
00000000 01111111 - from the most significant byte to the least significant byte (big-endian, BE), the most significant byte has a lower address.
01111111 00000000 - from the least significant byte to the most significant byte (little-endian, LE).
If a number is stored in big-endian format, the first byte must be skipped when reading it into a single-byte register. If a number is stored in little-endian format, the address of that number does not change—reading begins with the first byte in a register of any size.
Big-endian was used by IBM/360, Motorola 68000, and Sun SPARC processors.
Little-endian is used in Intel x86 processors. ARM processors use little-endian. The RISC-V processor architecture, which appeared later than the ARM architecture, uses only little-endian. Little-endian is used by almost all modern processors, and big-endian processors are a thing of the past.
Big-endian notation is more human-readable and is the default byte order used in technical literature.
For text files encoded in UTF-16, which stores characters in two bytes, the first two bytes at the beginning of the file (BOM, Byte Order Mask) determine whether the format is little-endian or big-endian. If these bytes are missing, the standard recommends using big-endian order.
CISC and RISC instruction sets
In the 1970s, while searching for ways to speed up computers, it became clear that of all the various commands that a processor could execute, the ones that were most often executed were a few simple commands: loading data from memory into processor registers, a branch command, simple bit operations, and returning values to memory.
An idea called RISC (Reduced Instruction Set Computing) emerged: removing slow-executing instructions and retaining the simplest ones, most of which would execute in a single processor cycle. Reducing the number of instructions was the goal, not the side effect. The reduction in time was achieved by standardizing the length of instructions along with their operands (instruction parameters), which allowed for a reduction in the number of transistors needed to implement the instructions.
----------------
The parameters of processor commands (instructions) are called operands because the commands perform operations (calculations) on data. Example: 1 + 2 equals 3. "+" is the operation. The numbers 1 and 2 are the operands. The "+" operation has two operands, so the operator is called binary (bi means two). There are unary operations, which have one operand. Example: NOT (negation): NOT true equals false. NOT false equals true.
---------------
The instruction set architecture used before RISC was called CISC (Complex Instruction Set Computing). CISC added complex instructions that could be implemented by logic elements in hardware to reduce the number of simpler instructions that could be used to implement a complex instruction.
An example of a complex command: compare strings. An example of a simple command: subtract one machine word from another. Complex commands can be replaced with a set of simple commands. Implementing complex commands in hardware allowed for the conservation of RAM, which was expensive at the time. A software task could be implemented using fewer complex commands, requiring less memory transfer. For example, if an operation on a character string is performed by a single command, then during its execution, there is no need to load code containing other commands from RAM. Memory gradually became cheaper, and the need for such conservation gradually diminished. For a long time, processor acceleration followed the path of CISC—hardware implementation of new commands and an increase in their number—and this was optimal. Intel used the CISC architecture for x86 processors, and this was justified.
As memory became cheaper, processor processing power became a bottleneck. Computations could be accelerated by parallelizing processor command execution. The following techniques are used for parallelization.
1) Pipeline. Complex instructions consist of a sequence of simple instructions. Instead of sequential execution (waiting for one instruction to complete and then moving on to the next), instructions are executed in parallel or staggered by one or more processor cycles, as long as they don't interfere with each other (use different parts of the processor).
2) Superscalar instruction execution. The processor consists of not one, but several functional units of the same type: arithmetic units, multipliers.
3) Speculative execution. For example, you need to check the condition a>0 and, if true, execute the command b=b+2 , and if false, execute the command b=b-2 . This condition can be written as follows:
if (a>0) then b=b+2 else b=b-2;
During speculative execution, the addition b+2 , subtraction b-2 , and evaluation of the condition a>0 are all executed simultaneously. As soon as the expression is evaluated, one of the two already-calculated results is taken and assigned to the variable b . If the number of instructions that can be executed in parallel is small, then "branch prediction" is used, meaning the instruction that is most likely to be executed is executed. For example, in most cases, the condition a>0 is true, since otherwise the programmer would have written a<=0 .
4) Out-of-order execution of instructions. If the operand values for the next instruction are unavailable, the next instruction ready for execution can be executed. The longer the pipeline, the more efficient out-of-order execution is.
5) Register renaming. If two instructions use the same registers during out-of-order execution, swapping the registers during compilation will allow the second instruction to execute concurrently with the first, since they will use different registers. The more general-purpose registers, the more likely the compiler will find free registers and compile the code so that the second instruction can be executed.
These acceleration techniques can be used together.
The problem with CISC is that instructions require different amounts of time (number of cycles) to execute, and instructions can have different lengths. This makes parallelizing instruction execution problematic. Instructions of the same length can be loaded as a stream from slow memory.
The Intel 286 (CISC) processor had 357 instructions and their variations, while the ARMv1 (RISC) had much fewer – 45 instructions and their variations. The smaller number of instructions in RISC is a consequence. The differences between RISC and CISC are:
1) In CISC, some instructions require a large number of clock cycles to execute. In RISC, efforts were made to eliminate such instructions;
2) CISC instructions can load data from memory and return it to memory, while RISC instructions work only with "registers" and include instructions for "loading data from memory into a register" and "returning data from a register to memory." Registers are small areas of memory within the processor for storing a fixed-length number (e.g., 32 bits); access to registers is performed in a single clock cycle. Instructions from RAM are transferred to a register, after which the microprocessor processes them;
3) RISC eliminated stacks and left only registers, the number of which increased. Compilers now have the ability to optimize: which registers to place data for calculations in order to minimize memory transfers.
--------------
A stack is a list organized according to the LIFO (last in, first out) principle . A stack is compared to a stack of papers: to take the second paper from the top, you must first take the first one from the top. In processors, stacks are used to store data.
--------------
The disadvantage of RISC is that the number of instructions in programs increases several times compared to CISC. The advantage is that decompiling code and finding vulnerabilities in executable programs is difficult for attackers, since code analysis requires attention to what was in the shared registers before control was transferred from another function. However, this also presents a disadvantage: to implement multitasking, the operating system must programmatically save the register state. The calling function must save the state, since only it knows which registers it will use. If the compiler can't predict which registers will be used, all registers are saved, which is time-consuming.
Using assembler to write programs for CISC processors was possible and made sense. Using assembler to write code for RISC is possible, but labor-intensive, as the large number of instructions required to implement what would be a single CISC instruction makes it difficult to follow the program logic. This is partially mitigated by assembler macros.
Hardware has evolved toward smaller chip components and smaller conductive connections, allowing for higher processor frequencies. Increasing processor frequencies allows for more instructions to be executed in the same amount of time. Current flow is not infinite, and long connections limit processor frequency. If data is transmitted over multiple connections simultaneously, the signal will be delayed over a longer connection.
The greater the number of transistors per unit volume of the chip crystal and the smaller the cross-section of the connections between them, the greater the heat dissipation, and the rate of heat dissipation is limited.
Since RISC processors have fewer transistors, RISC has an advantage. The Intel 386 was the last microprocessor with a classic CISC architecture. x86 processors adopted RISC architecture internally, but to support the CISC instruction set, the hardware decoder, which converted CISC instructions into a set of simpler instructions (microcode), became more complex. The decoder contains many transistors, occupies a large area on the silicon die, and operates constantly, resulting in high processor power consumption even when idle. In a processor using microcode, complex instructions are implemented as a set of simpler instructions. Subsequently, updatable microcode began to be used to control the decoder, allowing for corrections in the processor's hardware architecture and even the addition of new instructions.
Currently, the x86-64 instruction set is used primarily in computers, while RISC is used in specialized (embedded) equipment where low power consumption is important.
The RISC concept was implemented in RISC-I, MIPS, SPARC, PowerPC, and DEC Alpha processors. However, these processors offered no advantages (in performance, power consumption, or cost) over x86 processors and became obsolete. Only MIPS processors continue to be used in microcontrollers, where they compete with ARM.
The first processor to use the RISC concept was the RISC-I processor, created in 1982. It had 44,420 transistors and 32 instructions. RISC-II, released in 1983, had 40,760 transistors, 39 instructions, and was three times faster than RISC-I.
----------------------
IEEE installed a plaque at the University of California, Berkeley:
Students at UC Berkeley designed and built the first reduced instruction set computer (VLSI) in 1981. RISC-I's simplified instructions reduced the amount of hardware required to decode and execute instructions, allowing for a 32-bit address space, a large register set, and pipelined instruction execution. Paired well with C programming and the Unix operating system, RISC-I influenced the instruction sets of processors widely used today, including those for game consoles, smartphones, and tablets.
---------------------
ARM
In the UK, the BBC (British Broadcasting Corporation) commissioned the development of a computer from the Acorn company (which translates as acorn) for a national television show dedicated to computer literacy.
Due to the high technical requirements, the BBC rejected the contract from Sinclair, whose ZX Spectrum computer dominated the UK home computer market. The requirements included the ability to create programs, graphics for computer-aided design (CAD), sound support, and support for peripherals (such as printers). Home computers like the ZX Spectrum were primarily focused on gaming and had sufficient performance for gaming, but not for the BBC's requirements. At the time, games were simple, and computer graphics were used by design and image-processing programs. Graphics processing was handled by the processor, and its computing power was essential.
By the end of 1981, Acorn had developed a computer called the BBC Micro. 1.2 million units were produced, and these computers were used in English schools.
To meet Acorn's technical requirements, a 16-bit processor was needed. The Intel 80286, National Semiconductor 32016, and Motorola 68000 processors were considered. These processors were found to be slow, used RAM inefficiently, and were difficult to program in high-level languages to achieve the desired performance. In 1985, the ARMv1 (Acorn RISC Machine) processor was released, developed in just eighteen months by Acorn engineers. The processor used a new instruction set and architecture and was not compatible with existing processors. The processor contained 27,000 transistors. Similar processors, the Intel 80286, had 134,000, and the Motorola 68000, 68,000. The ARMv1 lacked cache memory, hardware units for multiplication and division, or floating-point calculations, yet programs executed an order of magnitude faster than on the Intel 80286.
The ARMv1 processor also had low power consumption: 0.1 watts. Processors with similar performance consumed tens of times more power, and therefore generated heat—several watts. Many years later, when mobile devices emerged, the low power consumption of the ARM architecture became its main advantage.
In 1987, the ARMv2 processor and the Acorn Archimedes computer based on it were released. However, existing operating systems and programs did not support this processor. Because of this, the computer failed to gain popularity, despite being quite powerful. The market was dominated by the IBM PC and Apple Macintosh, which ran PageMaker, Word, and Excel.
Apple decided to release the Newton pocket computer and was looking for a low-power processor. The Acorn ARM processor best met the requirements, and Acorn needed a large company to popularize the processor. In November 1990, Apple, Acorn, and VLSI (a processor manufacturer) formed ARM (Advanced RISC Machines). Since then, all processors used in the Apple iPhone and iPad have used the ARM architecture.
Games and computer graphics
In 1984, the computer game Elite was released for the BBC Micro and Acorn Electron computers, both manufactured by Acorn. The game featured wireframe 3D graphics and was a space simulator. The Elite universe consisted of eight galaxies, each with 256 planets. Galaxies were generated upon game launch. Galaxies were encoded with a small set of numbers, which were used as the seed for a pseudo-random number generator (PRNG) used to populate the galaxies. Upon subsequent launches of a saved game, the generator was initialized with the same set of numbers, and galaxy generation followed the same steps. The universe was restored exactly as it had been the first time the game was launched. The names and coordinates of stars remained the same. The game began on an orbital station on the planet Lave with 100 credits (currency) and a ship. The player flew the ship through star systems, battled other ships, and bought and sold goods. Earned credits were spent on equipping the ship with weapons, defenses, and increasing its cargo capacity. The game had no objective; the player explored space and could achieve the rank of Elite, which required winning 6,400 battles. From 1985 to 1988, Elite was ported to all platforms of the time: ZX Spectrum, Commodore, Apple II, Atari, Amiga, MSX, and IBM PC. To celebrate the game's 30th anniversary on September 20, 2014, Elite: The New Kind, a game faithful to the original, was released.
---------------
Example of game graphics:
Front view shows the ship's outlines and stars as dots. Short range chart shows a map of stars and a circle indicating the ship's range on a single tank of fuel. Front view shows the orbital station's outline as a polyhedron and a circle indicating the nearest star. The processor's power was sufficient to smoothly render the lines of the 3D outline and change the position of the stars.
-----------
The concept of Elite is similar to one of the first computer games, "Spacewar!" (Star Wars), created in 1961 for the DEC PDP-1 computer by Steve Russell , an MIT employee. The game was created because the computer had a display and wanted to demonstrate its capabilities. The game implemented control of the ship's trajectory with thrust and rotation, as well as missile launches. Inertia and gravity were taken into account in calculating the ship and missile trajectories according to Newton's laws. The player had to take these into account, anticipating how they would affect the outcome. This simple short-term planning added interest to the game and was used in Elite, particularly in the docking with the orbital station, and in Lunar Lander, a lunar landing simulation in which the player must neutralize the moon's gravity by using thrusters to maneuver and slow the descent under its influence. The second element that made the game interesting was the rapid change of the playing field, achieved through "hyperspace jumps." A random number generator was used for the starry background, which featured dots. The game's development took six weeks and 200 man-hours.
A simple game is usually the first program created when learning programming. People tend to replicate what they encounter when learning something new. When learning programming languages, they might even want to invent their own programming language.
-----------
Paul Allen, the founder of Microsoft, wrote in his book "Idea Man":
Every newbie needs a mentor, and C-Cubed had three of them. They were all world-class programmers, nerds with a touch of eccentricity. Unlike the business management, they didn't treat us like nuisances. I think they saw themselves in us as younger selves. Sometimes I felt like I'd stumbled straight out of high school and into a graduate seminar on advanced systems programming.
Steve Russell , nicknamed "Brake," the hardware chief, was short and plump, with a caustic sense of humor. At thirty-one, he followed John McCarthy from Dartmouth to MIT. There, Russell created the first truly interactive computer game, "Star Wars," on a PDP-1 computer.
Bill Weier, a thin, bespectacled man, spoke little. Known for developing SOS (Son of STOPGAP, one of the first text editors), he looked like a medieval scribe. I watched him slaving away at his terminal, creating complex structures of intricate code.
Dick Gruen, a former DEC consultant who met Russell and Weiher at Stanford, was the most outgoing of them all, a fan of fast food and dirty jokes, with a shock of curly hair. According to Gruen, there had never been an operating system he couldn't crash (an operating system crash that prevents it from running and requires a reboot). And you couldn't help but believe him.
To them, we were "Lakeside kids" (the school's name) or "testers." Occasionally, they'd tell Bill Gates and me to run multiple instances of a chess game simultaneously to crash the operating system. This task perfectly suited the adolescent urge to break things for fun, while simultaneously channeling that urge into something useful. As I later told a Seattle journalist, "The most effective way to learn is through hands-on experience with the best computer available at the time, learning how it works, and what it takes to make it or break it."
Another approach was to run stress tests (a type of testing to determine the limits at which a program can operate without errors) until the program crashed. We'd document on paper what we were doing that caused the crash and continue testing. The real trick was to freeze the operating system, which could be detected by the terminal freezing and buzzing when you pressed keys. Russell and Gruen would find the cause of the crash and be overjoyed, knowing they wouldn't be billed for DEC's CPU time, since the billing system had crashed along with the operating system. Bill and I were also overjoyed. As long as we found bugs, we weren't kicked out and were allowed to use the computer.
-----------
RISC-V
ARM sells licenses to produce ARM-based processors. The license includes the processor core design, software development tools (compiler, debugger), and the right to sell the resulting processors for a small fee per processor. Licenses vary widely, including ARM architecture licenses, which allow for the development of custom processors using the ARM instruction set, and licenses that use ARM patents, which do not require a fee per processor.
The RISC-V instruction set was introduced in 2010. In 2015, standardization rights were transferred to RISC-V International. In 2022, support for RISC-V instructions was added to the Linux kernel. In 2022, the manufacturer of the ESP32 microcontroller (SoC, system-on-a-chip) for the Internet of Things (IoT) began using the RISC-V instruction set. The transition to RISC-V is facilitated by the absence of licensing fees, which ARM has.
The RISC-V instruction set defines 32 general-purpose integer registers and 40 basic instructions for a 32-bit architecture. Instructions are 32 bits long, and the byte order is little-endian. The RISC-V instruction set is constantly evolving, with new instructions being added. Mandatory instruction descriptions (Instruction Set Architecture, ISA) are called "profiles." For example, profile RVA23 was defined in October 2024, following profiles RVA22 and RVA20. RVA23 now mandates instructions for vector operations, virtualization, floating-point instructions, and atomic operations.
The maker of Ubuntu, a popular Linux distribution, announced that it will only support processors with the RVA23 profile in the future. This means that future versions of Ubuntu will use vector operations and virtualization. If a processor lacks these instructions, the operating system will not be able to run on that processor. Requiring a mandatory instruction set simplifies operating system development—developers don't have to write code that replicates the actions the processor can effectively perform. Creating emulation code is a waste of developers' time, as such code is inherently slow, and software solutions lack scientific value.
The success of the RISC-V architecture will be determined by how well the Swiss-based non-profit RISC-V International develops standards compared to the British company ARM, which is owned by the Japanese company Softbank. Will RISC-V maintain a balance between the simplicity of hardware instruction implementation and the convenience of processor code generation?
EPYC is not EPIC
EPYC is the name of AMD's current processor series. The processor generations are named after Italian cities: Naples, Rome, Milan, and Genoa. The architecture of these processors utilizes a sophisticated spatial layout. The L3 cache is located on top of the processor cores, communicating with them via copper wires. This layout allows for a larger L3 cache and shorter interconnect lengths. Reducing interconnect lengths increases cache access frequency and reduces heat dissipation. The fast and large L3 cache delivers high performance and an advantage over competitors.
EPIC (explicitly parallel instruction computing) is a development of the VLIW (Very Long Instruction Word) processor architecture. The idea behind VLIW is for one "long" (many operands) instruction to describe several "short" (few operands) instructions that can be executed in parallel. "Long" instructions must be generated at compile time. In scalar architectures, instruction parallelization is handled by a hardware device in the processor—the instruction scheduler. The inventors of VLIW believed that removing the scheduler would reduce processor complexity and allow the compiler to analyze the program code more efficiently. However, the large size of the operands meant that they had to be loaded from main memory through caches. The compiler cannot predict the delays involved in loading operands from memory caches into processor registers. Intel decided to try developing a VLIW processor, adding architectural solutions to mitigate this problem. These architectural solutions were called EPIC. The word "epic" means legendary or astonishing. However, "epic" is also used in the phrase "epic fail." This didn't alarm Intel's management. Moreover, when the processor was released, it was named Itanium, which is reminiscent of the "unsinkable" ship Titanic, which sank on its maiden voyage. Unsurprisingly, the Intel Itanium processor was a spectacular failure.
There were attempts to use the VLIW architecture in other processors as well. For example, Transmeta, founded in 1995 when VLIW technology was still considered promising, created the Crusoe and Efficeon processors, which were unsuccessful. Transmeta stopped producing processors and tried to sell its patents to more successful processor manufacturers, but was unsuccessful. Ultimately, Transmeta was acquired by another company, which went bankrupt. The Elbrus architecture (ELBRUS, for ExpLicit Basic Resources Utilization Scheduling) is an evolution of VLIW.
The Itanium processor architecture is technically called IA-64, which is unrelated to the x86-64 architecture, just as EPIC is unrelated to EPYC. AMD created the x86-64 architecture. AMD designed the x86-64 architecture to be compatible with x86.
Arduino
In early 2000, programming courses were held in the Italian city of Ivrea. The courses used inexpensive boards with PIC microcontrollers, and a variant of the BASIC language for programming. PIC and BASIC aren't the best solutions, but they are the simplest and cheapest. Students and teachers created a board based on an ATmega 128 microcontroller and a simple development environment using a variant of the C language. Ease of use and open licensing made the Arduino project popular. The name Arduino derives from the "Arduino" bar in Ivrea, where the platform's founders gathered. The bar was named after the king of Italy, Margrave of Ivrea, who was elected king in 1002 (kings were elected at the time).
Using Arduino doesn't require extensive knowledge of electronics or programming. Arduino technology gained popularity, and peripherals emerged: expansion boards with standardized connectors allowing them to be interfaced with Arduino boards. Later, faster ARM and ESP32 processors began to replace the ATmega 128.
In addition to Arduino, there are also more powerful single-board computers such as Raspberry Pi, but their cost is significantly higher.
BBC micro:bit
Thirty years after the creation of the BBC Micro microcomputer, the development of which led to the development of the ARM processor architecture, the British broadcasting corporation BBC decided to replicate this success and launched a project to teach schoolchildren programming. They developed and distributed a single-board microcomputer, dubbed the BBC micro:bit, free of charge to 11- and 12-year-old British schoolchildren. In 2015, 1 million microcomputers were distributed to British schools. In 2018, 2 million BBC micro:bits were produced for distribution in 50 countries. The BBC micro:bit uses an ARM Cortex-M0 processor.
Microsoft has decided to contribute to the socially beneficial cause of educating schoolchildren and created a visual programming environment called MakeCode for the BBC micro:bit. The development environment is available free of charge as a web application at microbit.org or as a standalone app. MakeCode includes a BBC micro:bit emulator (a program that simulates the microcomputer's operation). The emulator allows you to test programs without owning a BBC micro:bit. In addition to visual programming, MakeCode supports programming in JavaScript and Python. Visual programming is designed for children aged 8 and up.
Programming for the BBC micro:bit is possible on the Arduino IDE using the C language, which is used by the Arduino IDE.
To display the results of the program's work, the micro:bit has 25 LEDs and two buttons for transmitting signals to the program.
Hoshen
The Bible (the first book ever printed by Gutenberg, rather than copied by hand) describes a breastplate (khoshen) to which were attached 12 multicolored stones (LEDs were not available at the time), arranged in rows of three in four rows. The stones each depicted six letters, making the alphabet 22. The board was used by the high priest as a terminal for receiving answers to his questions. Two devices, called "urim" and "thummim" (on/off), were connected to the board. The letters depicted on the stones were illuminated, and the priest interpreted the answer.
BASIC programming language
The BASIC (Beginner's All-purpose Symbolic Instruction Code) language was created in 1964 to teach non-programmer students the new subject of "Programming".
The BASIC language was designed for interactive use on terminals. At the time, teletypes—electric typewriters —were used instead of a screen and keyboard .
Example of a one-line BASIC program: PRINT 2+2
One could type one or more lines of a program and get a result. BASIC gained popularity after the release of the Altair 8800 microcomputer. BASIC was a good choice for the microcomputers of that era for the following reasons:
1) the language is simple and will be most convenient for microcomputer users;
2) The language is simple, and the interpreter won't take up much memory. Only FORTRAN could compete with BASIC in terms of interpreter code size, but it was more complex.
3) Microsoft founders Paul Allen and Bill Gates knew the language because they studied it at the school where they studied together.
2+2 or Hello Word!
In the first computers, to test their functionality, they wrote a program that would calculate 2 + 2 and display the result on the computer's output device. Output devices were called screens, monitors, terminals, displays, printers, and consoles.
Later, the first program was supposed to display the phrase "Hello word!".
The program consists of a small piece of code and is used:
1) to check that the software is installed and working correctly, and can compile and execute programs;
2) to illustrate the basic syntax of the language;
3) is traditionally written as the first program when learning a programming language.
The phrase "Hello word!" was first used in the 1978 book "The C Programming Language" by Brian Kernighan and Dennis Ritchie.
A similar phrase "hello word" was used a little earlier (in 1972) by Brian Kernighan in the B language manual.
Microsoft
The January 1975 cover of Popular Electronics magazine featuring the Altair 8800 computer inspired Bill Gates to write a BASIC interpreter. This was the first programming language for the first personal computer and the first program from Microsoft.
BASIC was created without a computer itself; development took place on a DEC PDP-10 computer, for which Paul Allen, even before the magazine with the Altair photo appeared, wrote an emulator and debugger for the Intel 8008 processor. Paul Allen and Bill Gates used the emulator to write a program for studying traffic flows. They wanted to sell traffic analysis services to municipalities for optimal traffic light settings. As soon as they wrote the program, states began providing such services to municipalities for free. The two friends' business venture failed, but they did end up with an emulator for the Intel 8008 processor.
Paul Allen adapted the emulator and debugger for the Intel 8080A processor used in the Altair, and Bill Gates wrote a BASIC interpreter for the Altair. The program was small—just under 4 kilobytes.
Bill Gates suggested that computer prices would fall, computers would become popular, computers would need software, and it would be possible to make money selling software.
Altair BASIC retailed for $150. It became popular among Altair 8800 owners, but owners preferred to share copies of Altair BASIC rather than purchase them. Microsoft suffered from software piracy from its inception.
On February 3, 1976, Bill Gates wrote an open letter to the computer community expressing his disappointment that most computer enthusiasts who used Altair BASIC had not paid for the program. The reason for writing the letter was that the income Bill and Paul received from selling the program amounted to a mere $2 per hour, which was quite low.
Microsoft subsequently created BASIC interpreters for all microcomputers. BASIC interpreters remained Microsoft's primary source of revenue until the advent of the MS-DOS operating system.
On April 2, 1980, Microsoft released the Z80 SoftCard expansion board for the Apple II computer for $349. Having licensed CP/M, it successfully sold CP/M copies in the same quantities as Digital Research. Moreover, the initial sales of the Z80 SoftCard accounted for half of Microsoft's annual revenue. The main driver of demand was the ability to run the popular WordStar text editor on the Apple II. Apple II computers were popular, but they did not support programs for the Intel 8080A or the Zilog Z80 processor, which was compatible with its instruction set.
CP/M and MS-DOS
The CP/M (Control Program for Microcomputers) operating system was written by programmer Gary Kildall in a programming language he wrote himself, which he called PL/M (Programming Language for Microcomputers).
In 1976, Gary and his wife founded Digital Research to sell copies of the CP/M operating system. By 1980, the company had sold 250,000 copies of the CP/M operating system. CP/M was the most popular operating system for computers based on the Intel 8080A processor. With the release of the Zilog Z80, Motorola 68000, Intel 8088, and Intel 8086 processors, CP/M was adapted for these processors.
In 1980, IBM recognized the potential of microcomputers as a platform for the corporate market. IBM approached Microsoft (which by then had sold half a million copies of its BASIC interpreter) to include compilers and interpreters for programming languages in the new IBM PC platform (the working title of Project Chess). IBM understood that computers are useless without programs, and programs are written in programming languages, so the new platform needed to have a high-quality set of programming languages. Microsoft released compilers and interpreters for many languages, including FORTRAN, COBOL, and Pascal.
Bill Gates persuaded the Chess project's leaders to use the newer Intel 8086 processor instead of the Intel 8080A. In September 1980, IBM began searching for an operating system for this processor, realizing that an operating system would also be useful. Paul Allen described the events of that time in his book "Idea Man":
--------------
Bill Gates called Gary Kildall and said, "I'm sending you some people, and I want you to treat them well because we're both going to make a lot of money on this deal." He didn't mention IBM by name, as the company insisted on utmost confidentiality. Coincidentally, Kildall was on a business trip, and his wife and business partner refused to sign the non-disclosure agreement and proposed her own form. The IBM project manager returned to Microsoft and said, "I don't think we can work with these guys; it'll take our legal department six months to get all the paperwork done. Do you have any other ideas? Could you handle this yourself?" Bill Gates was furious, as the entire project was at risk, as Microsoft didn't have its own operating system.
After a search, Microsoft acquired the rights to a 16-bit CP/M clone from Seattle Computer Products for $10,000, plus $15,000 for each company that would purchase a license from Microsoft. A total of $25,000, as Microsoft had only one client—IBM.
Where did the clone come from? Tim Patterson of Seattle Computer Products had been selling the SCP-200B expansion board for the S-100 system bus with an Intel 8086 processor since early 1980, but demand was low because customers wanted an operating system. Kildall promised to release CP/M-86, but never did.
Tim Patterson, in a hurry, wrote a 16-bit operating system with the working title QDOS (Quick and Dirty Operating System) from April to July 1980. After finishing QDOS, Patterson renamed it 86-DOS.
Patterson said, "We would have been happy if someone else had made the operating system. If Digital Research had released it in December 1979, there would be nothing in the world today but CP/M."
On November 6, 1980, IBM signed a contract with Microsoft worth $430,000: $75,000 for adaptation, testing, and consulting; $45,000 for the operating system; $310,000 for language interpreters and compilers.
--------------
IBM installed an operating system on its computers called PC DOS (Personal Computer Disk Operating System), while Microsoft sold copies of the operating system under the name MS-DOS for $40. After some time, Digital Research released CP/M-86 for the IBM PC, but due to its high price of $240, CP/M-86 was not in demand.
In 1982, a version of CP/M-68K for the Motorola 68000 processor was released. It was originally written in Pascal/MT+68k but was later rewritten in C. Porting to C made it easy to adapt CP/M-68K for the 16-bit Zilog Z8001 and Z8002 processors.
In 1988, Digital Research released an MS-DOS-compatible operating system based on CP/M for Intel 80x86 computers, calling it DR-DOS version 3.41. The version number was chosen to match the current version of MS-DOS. DR-DOS sold for $270, while MS-DOS sold for $40. Kildall justified the price difference by considering his operating system a professional product, while MS-DOS was a "toy." Users barely noticed the professionalism. A practical advantage of DR-DOS was the ability to password-protect directories and files. The idea of disk space delimitation was borrowed from CP/M. This was useful on corporate computers shared by many users, such as educational institutions. For ordinary users, such capabilities did not justify the price difference. DR-DOS's capabilities turned out to be incompatible with Microsoft Windows. DR-DOS fell out of favor after the advent of Windows. Not only capabilities but also program compatibility are important.
Part 3. Programs
Generations of programming languages
Machine codes (processor commands) are a first-generation programming language (1GL). On the first computers, commands were entered using switches on the computer console or using punched cards and punched tape.
Second-generation languages (2GL) include assemblers—program compilers (translators, converters) that convert assembly language text into machine code. Instead of machine code, assemblers use instruction and operand notations.
2GL = assemblers
Assemblers depend on the processor's instruction set and memory addressing methods. There is no universally used assembler syntax. The basic construct of the assembly language is a mnemonic code (mnemocode)—a processor instruction name abbreviated to 2-4 characters. An example for an x86 processor in Intel syntax:
mov eax, 7
Moves the number 7 to the eax register . The eax register and 7 are the operands of the mov instruction . Operands can be registers, constants, memory cell addresses, I/O port addresses, and labels. An instruction with such operands will be translated into B8 machine code .
There are two types of syntax for assemblers: AT&T and Intel. The main difference is the different order of operands. In AT&T syntax, the above command is written as:
movl $7 , %eax
The different syntax of the two types of assemblers makes programs difficult to read. AT&T syntax was developed for the PDP-11 assembler and is used for processor architectures other than the x86.
Moreover, even comments in different assemblers are incompatible with each other, three variants are used: " ; " " // " " # ".
Writing a program in assembly language is labor-intensive: you need to use a stack, a limited number of registers, to perform even the simplest operations. Assembly language programs are difficult to port to machines with different architectures.
With the advent of the C language, the need for assembly language began to decline. Programs written in C were just as efficient as those written in assembly language. Assembler use was limited to microcomputers, and then to microcontrollers—devices with limited memory and low performance, meaning programs were simple enough that a human could write a small program in low-level assembly language. "Assembler inserts" were also used: most code was written in a high-level language like C, while sections critical to performance or requiring direct access to hardware resources were written in assembly language.
---------------
The C language has influenced the development of all languages created since the 1980s. Some languages were created as direct successors (C++, C#, Objective C), but did not improve on C itself; others used its syntax and ideas.
Dennis Ritchie: "C is a quirky, imperfect, but incredibly successful language."
--------------
Assembler was used when a new processor or microcontroller was being released, but software for it hadn't been written yet. The lack of software wasn't an obstacle to processor shipments. Compilers for high-level languages for the processor were written and refined after the processors and microcontrollers were released. Once high-level language compilers were fully developed, assembly language inserts were gradually phased out. Nowadays, assemblers are rarely used, as high-level language compilers generate more efficient machine code than the average assembler programmer could write.
With the advent of assemblers, the concept of "source code" emerged (the textual representation of a program, which differs from the machine code understood by the processor). Assembly code was called source code. Assembly code was translated (converted) into machine code.
Assemblers use identifiers to mark the beginning of code sections, which greatly simplifies program writing. During translation, these identifiers are replaced by the address of the code section, which is only known after the program is completed.
Assemblers were the first to introduce constructs that were later developed in other languages:
1) Macros – the ability to name a section of code and specify the macro name alongside commands. The translator will substitute the code section for the macro. Macros with parameters are similar to subroutines (procedures). Macros are the "building blocks" of assembler programs. They significantly simplified coding.
2) Labels for transferring control (jump, jmp) to the marked code.
3) Directives are commands to the compiler. They allow you to influence the compiler process. Directives are the precursors to annotations ("pragmas"), which in high-level languages add declarative elements or expand the language's capabilities without changing its syntax.
4) Named constants, which allow you to give a name to a number and make it easier to change the value of the constant in the source code.
5) Comments. Without comments, it's difficult to understand assembly code.
While computers were simple and could solve simple computational problems, programming wasn't too tedious. As the tasks computers solved became more complex, writing programs in assembly language became more challenging.
3GL = high-level languages
The third generation (3GL) consisted of programming languages with a high level of abstraction (distance) from machine code. The first high-level language was FORTRAN (formula translator). FORTRAN was created between 1954 and 1957 by a group of programmers working at IBM under the leadership of Backus. The Plankalkül language could also be mentioned, but it was developed in isolation from the global community and did not contribute to the advancement of programming.
The second high-level language was B-0 (Business Language Version 0), also known as FLOW-MATIC. It was created for the UNIVAC I computer by a group of programmers led by Grace Hopper. B-0 served as the basis for the COBOL language, which became the primary language for developing business and economic software in the 1960s. Grace Hopper is known as the "grandmother of COBOL." COBOL was difficult to learn and write programs in; it had over 300 reserved words and 43 operators.
Almost all programming languages are 3GLs, so dividing languages into generations has become meaningless. Languages are now classified by other criteria, such as the paradigms they use.
You might encounter the distinction between 4GL and even 5GL generations, but the languages classified as such are no better than 3GL languages. 4GLs are highly specialized languages that solve a specific problem (domain-specific). These aren't even languages, but rather development tools that visually create declarative descriptions of program properties. The distinction between 3GL and 4GL is arbitrary.
The term "fifth generation" has come to be used for marketing purposes to refer to fourth-generation languages. People think "5" is bigger (newer) than "4," meaning better. Fifth generation refers to automated program creation tools using visual development tools, without programming knowledge ("low-code"). In other words, a programmer configures something in a visual development environment, and the development environment itself generates the program text in some universal language. The idea of creating a development environment where you don't have to write code, just click a mouse, has always haunted programmers. Typically, it all boiled down to the programmer needing to know how and what code is generated when performing manipulations in the development environment—that is, the programming language itself and the development environment. This proved more labor-intensive than writing a programming language outright.
TIOBE Index
This index evaluates the popularity of programming languages based on the number of search queries containing the language name. This means queries like "something language." The index does not rank languages based on the quality or volume of code written.
The most popular queries are for languages: C, Java, Python, C++.
Programming paradigms
A paradigm (model, thinking style) is how a programmer conceptualizes the process (logic) of data processing. Modern languages are multi-paradigm—you can write in different styles, but one style is dominant and easier to use. Examples of paradigms:
- Execution flow control: free (assembler, GOTO)/structured;
- Imperative/Declarative
- Procedural/Functional
- Algorithmic/Object-oriented
Algorithm
An algorithm is a set of instructions describing the order of actions to solve a problem. The word "sequence" was once used instead of "order," but as parallelization techniques were implemented in processors, the word "sequence" began to be replaced by the more general word "order." Instructions can be ordered in program code and executed in parallel within the processor, rather than sequentially.
Algorithms are as natural to human thinking as integers. For example, a recipe is an algorithm for preparing the dish.
Block diagram
A flowchart is a graphical representation of an algorithm. It is used to document how the algorithm works. Flowcharts were used when programs were written in assembly language or machine code. A program in a high-level programming language with comments describes the algorithm more simply than a flowchart. Programs in object-oriented programming languages cannot be described as flowcharts.
Flowcharts were used when studying algorithms before moving on to programming languages. This was appropriate in languages that frequently use GOTO (a jump operator to a program line whose name is specified as the operator parameter). An example of a flowchart describing an algorithm for calculating a factorial:
The C program corresponding to the flowchart is simpler:
a=1;
for(i=1; i<=n; i++)
{
a=a*i;
}
return a;
Before the advent of the C language, algorithms in scientific publications were described in the Algol language.
Graphical representation can be convenient, but it's not an end in itself. For example, diagrams using UML (Universal Modeling Language) are as "universal" as they are useless.
Typically, documentation is done as an afterthought and by less-than-qualified specialists. If you see diagrams you don't understand, that's normal.
If diagrams simplify development, they are useful. For example, class diagrams in object-oriented programming languages are useful. The benefit is that the development environment, based on the diagram, creates a set of template code files that can be modified by adding code.
Extended Backus-Naur Form (EBNF)
Developed by Wirth, EBNF is a simplification of Backus-Naur Form (BNF). BNF is designed to describe the syntax of programming languages. The advantage of EBNF is its simplicity and human-readability. EBNF uses only 10 special characters: [ ] { } ( ) | = " (three types of brackets, the vertical bar, the equal sign, quotation marks, and the comma). The syntax is defined by five rules. EBNF is an ISO/IEC 14977 standard. There are no other standards for describing syntax, so EBNF is used in documentation. Example of a command description in EBNF:
CREATE OPERATOR name (
{FUNCTION|PROCEDURE} function_name
[, LEFTARG type_left ] [, RIGHTARG type_right ]
[, COMMUTATOR commutator_operator ] [, NEGATOR inverse_operator ]
)
Curly braces {|} are a set of phrases separated by the | sign , which has the meaning of OR. Phrases in square brackets are optional. An example of a command that fits this description:
CREATE OPERATOR == (
FUNCTION equals,
LEFTARG string,
RIGHTARG string,
NEGATOR <>
)
Backus developed the FORTRAN language. Wirth developed Pascal to teach students structured programming, but it fell into disuse and declined in development. Pascal is not bad for educational purposes, but learning the syntax of a language that isn't used in practice is unwise.
In the wake of the popularity of object-oriented programming languages, Apple created the Object Pascal language in 1986. Wirth was not involved in the creation of Object Pascal, just as Thompson was not involved in the development of C++. It is noteworthy that a dialect of Object Pascal is the once-popular Delphi language, about which one can say something similar to what Dijkstra wrote about BASIC in 1975: "COBOL programming is brain-damaging. Therefore, teaching it should be treated as a crime." Currently, Pascal-like languages are not encountered and pose no danger to the minds of programmers.
Regarding the BASIC language, Dijkstra wrote: "It is virtually impossible to teach students who have previously studied BASIC good programming. As potential programmers, they have suffered irreversible mental degradation." There's nothing wrong with writing your first programs in BASIC, but using it as your primary programming language is not recommended.
The same can be said, somewhat humorously, about JavaScript, which is as widespread as COBOL once was. Using JavaScript reduces the programmer's memory to a few lines of code, resulting in an inability to design programs (conceptual thinking).
--------------
Dijkstra was known for his caustic aphorisms. His colleague Alan Kay coined a Dijkstra-esque aphorism: "Arrogance in computer science is measured in nano-Dijkstras." Regarding Dijkstra's aphorisms, Kay said: "The two biggest problems in our not-quite-field are those who listened to him too carefully, and those who didn't listen to him carefully enough."
--------------
Structured programming
In 1966, mathematicians Böhm and Jacopini proved the following theorem. A program specified as a flowchart can be represented as three control structures:
1) sequence of execution - an arrow for transition from block to block on a flowchart;
2) the conditional operator IF THEN ELSE, which implements branching, branching the flow of executed commands;
3) cycle.
The essence of the theorem is that the implementation of algorithms is possible without the GOTO transition operator.
At that time, the GOTO jump statement was often used, resulting in confusing programs and making it difficult to understand how the program worked. GOTO was used because machine code and assembler languages lacked instructions for implementing loops. Loop logic and control of instruction flow were implemented using the jump instruction , similar to GOTO. Programmers who wrote low-level code continued to use what they were accustomed to when transitioning to high-level languages.
The GOTO problem illustrates that the choice of programming language influences the way we think and reduces the likelihood of writing efficient and high-quality code in the future when we switch to other programming languages and development tools.
Hoare, Wirth, and Dijkstra created structured programming. Dijkstra formulated simple principles:
1) the GOTO transition operator should be abandoned;
2) the program is built from three control structures: execution sequence, branching, cycle;
3) control structures (blocks) can be nested within each other;
4) repeating fragments (of code, a set of blocks) can be designed as “subroutines” (procedures and functions) - programs with one input and output;
5) a logically related group of instructions should be designed as a block;
6) all structures must have one input and one output;
7) Programs should be developed top-down (from the general to the specific). Start with the input blocks (what parameters the program accepts) and the output block (what status or data the program should return), then the main parts as subroutines. Implementation (coding, creating a sequence of operators in the programming language) comes later. You can create "stubs" of subroutines without implementing them, which allows for rapid program prototyping.
Blocks
A block is a grouping (designation) of consecutive commands (instructions, operators, function calls, other blocks) in a program's source code. Variables (data structures, functions) defined within a block are "local"—visible only within the block. When exiting a block, local variables disappear and the memory they occupied is freed. Blocks:
1) help manage the lifetime of data and the scope of variables (data structures);
2) allow a set of commands to be represented as a single whole;
3) can be nested one inside the other.
A block can be thought of as an intermediate step to subroutines (procedures, functions, modules, methods), since a block is always the body of a subroutine. Blocks have no parameters, but since they are defined in the same location as the block code, all variables defined in the block in which they reside are visible. In other words, blocks have a "transparent" boundary.
In JavaScript, blocks are associated with subtle properties that make them difficult to use. These properties are counterintuitive and unintuitive, and if left unnoticed, they can lead to side effects.
Block designation
Blocks are used very frequently in modern programming languages, and their syntax must be simple. In C and C-like languages, blocks are denoted by curly braces: {} . This is intuitive and natural. Ada Lovelace used curly braces in her first program to group statements into loop bodies. Surprisingly, curly braces were not used before the advent of the C language. Instead, the English words BEGIN and END , which came from Algol, were used. These words contain many letters, which makes programs less readable. Following the idea that English words are more pleasant and understandable for programmers made writing code awkward. Most of these languages are no longer used. They are not used only because of the words " begin-end " instead of " {} ". These words are a marker indicating that unnatural decisions were made in the languages and elsewhere.
The Ada language attempted to address this shortcoming by making the use of begin and end optional, but introduced terminating suffixes for control structures. This made coding even less intuitive. The PL/SQL and plpgsql languages, used in relational databases, inherited the Ada syntax. Example:
begin
if a>0 then
a=a+1;
a=a+1;
end if;
end;
After then comes a set of commands without a block designation. This is illogical and makes the code harder to understand. In C-like languages, it would be written like this:
{
if (a>0)
{
a=a+1;
a=a+1;
}
}
Python, which was developed in 1991, after C, uses indentation—invisible characters like spaces and tabs—to denote blocks. This is reminiscent of the use of spaces in place of zero in the Babylonian numeral system.
--------------
The creator of the Python language justified the use of indentation as follows:
"Using indentation reduces visual clutter and makes programs shorter, thereby reducing the amount of attention required to perceive a basic unit of code. Second, it gives the programmer less freedom in formatting, thereby allowing for a more consistent style, which makes other people's code easier to read (compare, for example, the three or four different conventions for placing curly braces in C, each with strong proponents)."
In other words:
1) saving on symbols {}
2) Encourage programmers to use indentation for formatting. Indentation improves program readability, but it's inconvenient to count invisible characters.
Don't take the language creator's reasons for creating it at face value. They might have forgotten to mention that they did it for fun. The name Python comes from the comedy television show "Monty Python's Flying Circus."
-------------
Ultimately, history preserves the best decisions, but at any given moment, many decisions exist, and they can persist for a long time. For a long time, people believed that the sun revolved around the earth or that zero was not a natural number. What proportion of decisions will not survive? Most likely, according to the Pareto principle, it's 80 to 20. Therefore, it's not worth following the majority. It's better to trust yourself, not follow other people's ideas or "principled considerations."
Placement of curly braces
It's fair to say that the placement of curly braces is a matter of personal preference. It's worth exploring how this diversity arises.
In the C language, the place of curly braces was given by Kernighan and Ritchie in their book "The C programming language":
main()
{
printf("hello, world\n");
}
Regarding the placement, the book states: "The placement of parentheses is less important, although people are passionate about their own styles. We've chosen one of the popular styles. Choose the style that suits you and stick to it."
Those who have read the book will arrange their braces as in the book. This is natural and logical, and 20% of programmers in C-like languages use it. How do 80% of programmers arrange their braces? Because they were arranged in the languages they learned programming in.
It can be assumed that the style is:
if a>0 then
a=a+1;
end if;
led to the following style of arrangement of curly braces:
if a>0 {
a=a+1;
}
Even Kernighan and Ritchie use this style for statements, but not for function bodies and blocks.
There is also a variation:
if a>0
{
a=a+1;
}
which is called the "GNU style." GNU was popularized by Stallman. It is believed that Stallman's use of indentation before curly braces was influenced by his experience programming in LISP.
In the Allman and GNU styles, blocks are balanced and symmetrical. Asymmetrical blocks are more difficult to read.
The origin of the C language
In 1957, IBM developed FORTRAN, the first high-level language.
In 1958, the Algol language (algorithmic language) was developed at a week-long conference in Zurich. It inherited much from FORTRAN, but the core concepts were organized into a more logical structure. Algol introduced code blocks and recursion. Algol is a procedural, imperative, structured language with strong typing. Two years later, the language specification was finalized and named Algol-60.
In 1963, CPL (Combined Programming Language) was created based on Algol-60, offering more options for interacting with hardware. Algol-60 was minimalist and not suitable for solving complex problems. CPL was overcomplicated, but a few years after its introduction, BCPL (Basic Combined Programming Language) was created from it. The functionality that complicated program compilation (translation into machine code) was removed from CPL, so the word "Basic" was added to the name.
The CPL language was unremarkable, but in 1969, AT&T employees Thompson and Ritchie created a language based on it, calling it " B. " B had the semantics of BCPL and the syntax of small Algol (a subset of Algol-60 designed for small computers). In other words, B looked like small Algol but ran like BCPL. Since B incorporated only the parts of BCPL that Thompson considered most useful—roughly a quarter of what BCPL had—they decided to drop a third of the letters from the name "BCPL." Thus, "BCPL" became " B. "
The B language was designed for writing systems programs. It was a typeless language with a single data type—the machine word. Depending on the context, values of this type were treated as integers or memory addresses. Both B and BCPL were interpreted, meaning no compiler was created for them.
From 1969 to 1973, Thompson and Ritchie rewrote the Unics (Uniplexed Information and Computing Service, later renamed Unix) operating system code in B. In 1972, the second version of Unix, rewritten in B , was released . During the rewrite, the language was revised. Structures were added to the language—variables that store multiple individual values in a related (structured) way—which significantly simplified programming. Ritchie and Thompson considered the addition of structures, which were absent from B , small Algol, BCPL, and CPL, to be significant enough to give the language a new name, and B became C. This is how the " C " language (pronounced "See") was born.
C language
The C language was developed over several years during the process of porting operating system code to it, and the result was both user-friendly and simple. C was the first language that didn't try to impose any particular programming style or adhere to any particular paradigm. C was the first high-level language to provide access to all processor capabilities, such as "pointers"—references to areas of RAM—and bitwise shift operations, which began to appear in processor instructions.
A compiler for the new C language was included with the third version of the Unix operating system, released in 1973. That same year, version 4 of Unix was released, with a kernel completely rewritten in C.
In 1975, Unix version 5 was released, completely rewritten in C. Since 1974, Unix source code in C has been distributed among universities. Unix and the C language have gained popularity. By 1978, Unix was installed on more than 600 computers. The success of the C language was further enhanced by the publication of "The C Programming Language" by Kernighan and Ritchie in 1978. The 228-page book was simple and clear. It does not use Backus-Naur Form (BNF) to describe the language syntax.
In seventh grade, Ken Thompson became interested in binary arithmetic. He read several mathematics books and learned binary arithmetic operations. He had a mechanical adding machine, similar to an abacus, and built a similar device for binary arithmetic. In his senior year, Thompson became fascinated with electronics and wanted to build an analog computing device, but after enrolling at UC Berkeley, he gained access to computers and focused exclusively on them.
-----------------------
From Thompson's speech at the National Inventors Hall of Fame:
I was in seventh grade. I became friends with the owner of a local radio store. He let me do what he called "work"—repairing radios and anything else I could do, which wasn't all that great.
Later, I wanted to build a five-transistor radio. The first and only commercially available transistors cost over five dollars each. This was far beyond my budget, but I started saving anyway. The store owner told me he could find these transistors for under a dollar each. That's exactly how much I saved up for those five transistors. So, I bought the transistors, built the radio, and now I'm here on this stage.
It never occurred to me that my father and the store owner bought the transistors and sold them to me for exactly the price I could afford.
This is just one story of many that have led me to where I am today.
-----------------------
Games and programming
Games help children explore the world. When people first encountered computers, the most obvious thing was computer games. Games provide an incentive to learn about computers. Some people develop a desire to study the logic of a game, how it works, and then to write their own game.
Computers of that time had an interpreter or compiler for some programming language, usually BASIC. People started with games with simple logic and implementation: tic-tac-toe, Go, Ladder, Xonix. However, creating computer programs was more enjoyable. Once you learned how to create your own programs, the interest in playing faded, just as it did in childhood, after you'd sufficiently explored the world.
----------------
From Ken Thompson's interview "Pushing the Limits of Technology: The Ken Thompson and Dennis Ritchie Story":
Unix was created for me.
I didn't create Unix as an operating system for other people,
I started creating Unix to play with and for my other activities.
I have always been into games, games were my element.
I played pinball on arcade machines and picked the locks on the back doors of the machines. I studied the circuit diagrams they contained.
This is how I learned the logic of program construction.
----------------
Microsoft Flight Simulator was released in 1982 and could even be used to learn how to fly airplanes.
------------------
From Richard Feynman's book "Surely You're Joking, Mr. Feynman!":
As for Mr. Frankel, who started all this activity, he began to suffer from computer fever—everyone who works with computers knows about it these days. It's a very serious illness, and it's impossible to work with it. The trouble with computers is that you play with them. They're so wonderful, so many possibilities—if it's an even number, you do this, if it's an odd number, you do that, and very soon you can do more and more sophisticated things on a single machine, if only you're smart enough.
...if you've ever worked with computers, you understand the fascination with seeing how much can be done.
------------------
Games are a stage in human development. After interest in games wanes, another interest emerges: finding bugs in programs and proving one can do better—that is, "hacking" the system, as Paul Allen and Bill Gates began. Steve Wozniak, the founder of Apple, created a digital device called BlueBox in his youth, which created sounds similar to telephone control signals. The device allowed long-distance phone calls to be made without charges. Steve Wozniak and his friend Steve Jobs entertained themselves by making prank calls. One day, Wozniak called the Vatican and, posing as Henry Kissinger, asked to speak to the Pope. The friends manufactured and sold the BlueBox, but it was risky and not entirely legal. They stopped making it and created their own computer and company, Apple.
The desire to "hack" a system stems from childhood—it's the desire to take the subject of study apart. As children, we take apart cars and toys to see what's inside. We also test boundaries and "rebel," and this is also a stage of development. Hacking is the study of how programs work. For languages that compile to machine code, such as C, decompilation into assembly code is possible. Based on the results of this study, we create our own programs or digital devices—in other words, we create something new. Destruction is an intermediate stage, and without a transition to creation, a person does not develop. Steve Wozniak and Steve Jobs, having quickly passed the "destruction" stage, created Apple and achieved success in life.
Games and hacking are a way to understand the world. Those who linger at these stages stop developing. For example, you can disassemble a computer or laptop to figure out how it works. You're unlikely to find anything interesting; the most interesting things (programs) are stored in the computer's memory. Creation means disassembling without destroying, cleaning and repairing, perhaps refining, and then reassembling.
Assembling circuits from semiconductor components is also one of the stages of understanding the world. Ken Thompson built a radio, Steve Wozniak built the BlueBox telephone device. They completed these stages and moved on to university studies and programming. Using physical (material) devices (construction sets, robots, microcomputer boards) is interesting in childhood. As abstract thinking develops, physical devices become unnecessary; software emulators of physical devices are sufficient. Paul Allen and Bill Gates developed BASIC for the Altair computer without having one; they developed it using an Intel 8080A processor emulator on a DEC PDP computer.
System and application programming
Systems programming is the creation of programs that support other programs. Examples include operating systems; development, compilation, assembly, launch, and execution environments; drivers; utilities; database management systems; application servers, virtualization; and device emulators.
Application programs are those that solve business problems and interact with users. For example, text and visual editors, games, email clients, browsers, accounting, and warehouse programs.
The concept of systems programming emerged in the 1950s and 1960s with the development of compilers, elements of operating systems for the first computers. At that time, programs were written in machine code and assembler languages. In the 1960s, high-level languages like Algol began to be used. COBOL was used for application programming.
For creating operating systems and drivers, programming languages that provide direct access to the hardware at the "low" (close to the hardware) level of ports and I/O buses are best suited. Assemblers and the C language provide this access, as it was created and refined during the operating system's development.
In systems programming, knowledge of hardware architecture, data structures similar to those used by the hardware, efficient data processing algorithms, and the operation of memory at all levels are essential. Solving systems programming problems can be quite complex, and an idea for how to implement the task may not immediately emerge. Some tasks must be revisited after a while. For example, a task may be suspended until other tasks on which the suspended task depends are completed.
In applied programming, tasks can be broken down into small, isolated subtasks that can be solved in a short period of time. Many tasks are routine (repetitive), so applied programming tasks can be solved using generative artificial intelligence. In applied programming, one can ignore hardware and memory efficiency and focus on implementing the task in the simplest (in terms of labor costs) way possible—the main thing is that the program works and produces results. Applied programming is less labor-intensive than systems programming; the need to create application programs is higher, and the entry barrier (the skills required for effective work) is low. Routine tasks are easier to automate than complex ones; generative language models can solve them.
Data types
In 1976, Wirth's book "Algorithms + Data Structures = Programs" was published.
Programs use control structures to process data. Data is the medium of information. Data is processed by commands (operators).
A data structure is a data carrier, allowing the storage of similar and/or logically related data. For "processing" (adding, searching, editing, or deleting data), a data structure provides an interface consisting of functions (operators). An operator is a shortcut for calling a function. Example: " a + b " is an expression that uses the addition operator and has two operands (arguments, parameters). The equivalent function is: " sum(a,b) ". Notation with an operator is more compact because it uses fewer characters.
To create high-level programs that solve real-world data processing problems, it's convenient to use data types that closely resemble real data. For example, dates, times, text strings, coordinates, and the color of pixels on a screen. Therefore, high-level languages have a set of data types most commonly used in the tasks for which the programming language is intended. For convenient data storage, languages include arrays and other structures that allow processing of data sets as a single unit. Languages can also allow the construction of custom types (object classes) and the inclusion of libraries (modules) that define types and tools for working with them: operators and functions.
Typification
Programs receive, process, and output data. One level of language classification is typeless and typed. Typeless languages include assembly language and B language . In these languages, data is represented by numbers corresponding to the processor register sizes: 16, 32, or 64 bits. No type checks are performed during program execution, only basic checks based on the physical architecture. For example, when compiling an assembler program, a build error will occur for the instruction mov cx, eax ; since the cx register is 16-bit, and the eax register is 32-bit. The absence of checks during program execution increases performance. The disadvantage of typeless languages is that it is inconvenient to work with data with a complex structure, such as strings (which require working with parts of strings the length of a machine word) and collections. Complex data types are needed for application programs.
Typed languages can be statically/dynamically typed, weakly/strongly typed, or explicitly/implicitly typed. C has statically, weakly, and explicitly typed languages. Java has statically, strongly, and primarily explicitly typed languages, although some elements of implicit typing are rarely used.
Dynamic typing means that data handling checks are performed at runtime, not compile time. Programs written in dynamically typed languages require extensive testing, but it's impossible to catch all errors.
With static typing, data type validation is performed at compile time. Runtime checks are eliminated, and the program runs faster. Static typing simplifies code writing, as development environments, knowing the data type, can provide a list of valid operations and data manipulation methods, perform word completion, and provide hints. An example of a variable declaration with static typing:
int i; // variable i will store integers of type int
Dynamic typing:
var i; // variable i will store unknown value
At first glance, dynamic typing allows for the creation of "universal" code that handles any data type. It also creates the appearance of simplicity—no need to puzzle over type selection. This simplicity is deceptive, as it complicates error detection and testing. Code that handles arbitrary data is easily written in strongly typed languages such as Java. Dynamic typing is used in Python and JavaScript.
------------
The Ada language logo with the inscription "We believe in strong typing." The inscription and color are an allusion to the inscription and color on dollar bills.
------------
Weak typing allows for implicit type conversions (casts). This eliminates the need for type casting constructs. The downside is that it can lead to loss of precision or a type cast that the developer is unaware of. The line between weak and strong typing is blurred. For example, Java uses the concept of boxing/unboxing—automatic casting of primitive types (such as int) to object types and back—to address an unfortunate feature of Java. Collections cannot store primitive types. Nevertheless, Java is considered a strongly typed language. C is considered weakly typed, but in practice, this does not lead to ambiguities. The reason is that C does not have many data types, and creating custom types is complex, leading programmers to use simple types. C++ allows for many complex types, and when creating C++ programs, the disadvantages of weak typing become apparent, making it difficult to create high-quality programs. Complex types are used in application programming. In application programming, it is convenient to write programs in an object-oriented style. Java is a good language to learn object-oriented programming, but C++ is not.
Explicit typing means explicitly specifying the variable's type along with its name. Using explicit typing makes code easier to read. It's immediately clear what type a variable can store or what type a function will return. An example of explicit typing:
boolean equals(int x, int y);
With implicit typing the notation is shorter:
def equals(x,y);
Languages with explicit typing may have elements of implicit typing. For example, Java has the diamond operator ("<>"). Programming languages evolve, and they acquire features that have proven themselves in other languages.
Models
A model is a representation of an object or process in any form (mathematical, physical, symbolic, graphic, or simply descriptive).
First, a "heuristic" model is created—images in a person's imagination. The ability to perform such modeling depends on imagination, experience, and erudition.
Further, intermediate models can be created for detailing: diagrams, flowcharts, charts, drawings.
Next, an "information" model is created—a description of the essential properties, possible states of the object, the processes of state transitions, and the relationship with the outside world (data input and output). Data types are selected. Properties include relationships, constraints, rules, and operations.
Interacting with a computer: dialog and batch modes
Interaction with the first computers was done in batch mode. Programs were written on sheets of paper in a format similar to that used by Ada Lovelace to write the first computer program. An example of a program format in assembly language:
The program was then transferred to machine code on punched cards, and the punched cards were sent for execution. An example of a program printout in machine code for the IBM System/360 and a stack of punched cards containing the program:
After some time, the result would be displayed. If the program contained an error, the cards had to be re-punched, sent for execution, and then waited for the result. The reason for using batch mode was that there were no operating systems or programs that would restrict client access to the computer.
After the batch mode, a "dialogue" mode was implemented. Commands were sent to the computer and a response was received. Several terminals were connected to a single computer, and several people could share a single computer. This mode is used for communicating with language models in chat mode: the terminal is an internet browser or mobile application. A teletype (an electronic typewriter) was used as a client. Later, monitors (displays) with keyboards began to be used instead of teletypes, and floppy disks replaced punched cards and punched tape. Nowadays, flash drives are used instead of floppy disks. Later, personal computers appeared, which did not require access restrictions.
Initially, terminals displayed only text and printed it line by line. Operating systems and databases still use text-based consoles running in dialog mode as the standard client application. Later, "pseudo-graphics" symbols appeared in the command line—lines, graphic symbols like ╔═╗╚╩╝☺—and then a graphical mode. First, text mode, and then graphical mode, began to use windows to display data. Windows are convenient because they make it easier to perceive information piecemeal. The Windows operating system was created. Over time, the information content of the graphical interface began to decline, as a large number of graphic elements and images appeared that had no semantic content.
When writing and testing programs, it's enough for the program to output text; a console is sufficient for this. Input data can be passed to the program by setting variable values in the program text. When introducing programming, books and training courses initially use a simple text editor and command-line utilities. This allows you to focus on the core task at hand. A black-and-white text console is suitable for this purpose. When learning something new, the amount of data they can remember is limited.
An example of editing a C program in the mousepad text editor and then compiling and running it in the Linux operating system text console :
An example of running the same program in the Eclipse graphical development environment:
The Eclipse window has many buttons and menus. Installing Eclipse and compiling and running a simple program makes writing programs and learning the language more convenient than using the console. In Eclipse, you can step through a program using the debugger. Stepping through a program makes it easier to remember how it works.
Setting up a development environment, like getting started with any program, can seem complicated. It requires observation, basic logic, and intuition to navigate them. For example, suppose you want to run a program in a debugger. How do you do that? In the image, you can see a button with a green bug icon. The trick is to right-click on the line number and select "Toggle breakpoint" to stop the debugger when it reaches the line where the breakpoint is set. Here's an example of a challenge:
When I clicked the green bug button (the debugger, which fixes bugs), Eclipse displayed the error message "Unable to run gdb: reason unknown." This is because the Eclipse developers failed to check whether the gdb debugger is installed before launching it. Checking for the presence of a program before launching it is similar to checking whether a variable has been assigned before reading its value. Forgetting to assign a variable is a common programming error. Eclipse is designed for programmers, and they should learn to solve small problems.
The image shows an example of running the gdb --version command in a terminal window , which returned the error: " gdb is not installed, but you can install it with sudo apt install gdb ." This is an example of a user-friendly message. After running the command, the debugger in Eclipse will launch successfully.
Recursion
A recursive subroutine call is one of the algorithms. Recursion is the call of a function (procedure) from within itself, either directly (simple recursion) or through other functions (complex or indirect recursion). Recursion is more complex to understand, but it allows for the creation of efficient programs.
The implementation of recursive function calls in practically used programming languages and environments relies on the call stack.
----
A stack can be thought of as a tube into which balls are pushed one by one. Balls can be removed from the tube, starting with the last one. To reach the first ball inserted, all the balls inserted after it must be removed. This order of ball removal is ideal for recursive function calls and returning their results.
----
The address to which control should be returned upon function exit and the function's local variables are stored on the stack, ensuring that each subsequent recursive call to the function uses its own set of local variables and thus functions correctly. The downside is that each recursive call requires memory, and with deep recursion, the stack may run out of memory.
Theoretically, any recursive function can be replaced with a loop or manual stack manipulation. However, such modifications are generally pointless, as they merely replace the automatic context saving on the call stack with manual execution of the same operations with the same or greater memory consumption. FORTRAN, COBOL, and PL/1 initially lacked recursion, and this was a drawback of these languages.
An example of a recursive function call to calculate a factorial in C:
#include <stdio.h>
long factorial (long n) // function definition
{
if(n<=1) return 1; // checking the function exit condition
return n * factorial(n-1) ; // recursion - calling a function within itself
}
int main() // the main function from which program execution begins
{
printf("%ld\n", factorial(20)); // print the result and call the function
return 0; // return program status
}
Compilation:
cc factorial.c -o factorial
Execution:
./factorial
2432902008176640000
The resulting number is 64-bit (8-byte). Although the long type is guaranteed to store only 32-bit numbers, on 64-bit processors, calculations are 64-bit, and changing the type name " long " to " long long " and the format " %ld " to " %lld " is not necessary.
When calculating the factorial 21! = 51,090,942,171,709,440,000, the program will return an incorrect result because it does not fit into 64 bits. The maximum value for an unsigned 64-bit integer is 9,223,372,036,854,775,807.
A function with a recursive call can be replaced by a function with a loop:
long factorial(long n)
{
long result=1;
for (long i=2; i<=n; i++) result = result * i;
return result;
}
You can see what the program code would look like if it were written in assembly language. The C compiler will output the assembly code to the file factorial.s with the command:
cc -S factorial.c
The created factorial.s file with assembly code will have at least 80 lines, of which the factorial calculation will require about 10 instructions (mnemonics) in assembly.
An example of a factorial function in x86 assembly language. File fact.s:
.globl fact
fact:
movl $1, %eax # place the number 1 into the eax register (eax=1)
movl %edi, %ebx # copy the value of edi to ebx (ebx = edi)
L1: cmpl $0, %ebx # compare the value in ebx with zero (ebx==0)
je L2 # jump to L2 if the comparison is true (goto L2)
imul %ebx, %eax # multiplication (eax = eax * ebx)
decl %ebx # decrement (ebx = ebx-1)
jmp L1 # goto L1
L2: ret # exit the function (return)
The eax, ebx, and edi registers are also present on 32-bit x86 processors, and on them, the maximum number for which the factorial can be calculated is 12!=1932053504.
On 64-bit x86-64 processors, the code will be compiled using 64-bit registers. You can use the 64-bit register names by replacing the letter " e " with " r ":
.globl fact
fact:
mov $1, %rax # put the number 1 into the rax register (rax=1)
mov %rdi, %rbx # copy the value of rdi to rbx (rbx = rdi)
L1: cmp $0, %rbx # compare the value in rbx with zero (rbx==0)
je L2 # jump to L2 if the comparison is true (goto L2)
imul %rbx, %rax # multiplication (rax = rax * rbx)
dec %rbx # decrement (rbx = rbx-1)
jmp L1 # goto L1
L2: ret # exit the function (return)
C program for calling an assembler function (file fact1.c ):
#include <stdio.h>
extern long fact(long);
int main()
{
printf("%ld\n", fact( 20 ));
return 0;
}
With 64-bit numbers, it is possible to calculate the factorial of 20 .
Why use C code? An assembly language program that prints text to the console would have many commands, but in C, the printf() function is sufficient .
Compiling a C program and assembly code:
cc fact1.c fact.s -o fact1
or another popular compiler:
clang fact1.c fact.s -o fact1
Executing the compiled program:
./fact1
2432902008176640000
On x86 computers, up to two integer parameters can be passed to the called function via registers. The first parameter is passed via the rdi ( edi ) register, the second via the esi ( rsi ) register. The return value is taken from the eax ( rax ) register. On 32-bit processors, a 64-bit value can be returned; the most significant bits are taken from the edx register . Larger values must be returned via memory, as accessing memory is much slower than registers.
On x32-64, up to six parameters can be passed to a function via registers. Parameters three through six are passed via registers rdx, rcx, r8, and r9 . Passing parameters via registers is extremely fast. If more parameters need to be passed, or the parameter types are complex, the values are passed via RAM, which is slow.
In the example, using assembly language didn't add any functionality compared to the factorial.c program , written in C. Furthermore, assembly language code is only suitable for x86; it won't compile or run on other processors. Assembly language code is useful for studying how C language operators are converted into processor commands, how a program runs, or how it calls operating system functions.
Scripting programming languages
Operating systems have a utility program - a text console (terminal, command line, shell), where you can interactively (in "dialogue" mode with the operating system) execute commands.
To execute commands based on a conditional algorithm or repeatedly (in a loop), scripts written in scripting languages are used. These languages typically include the words "script" or "shell" in their names, for example, ECMAScript (its dialects JScript, JavaScript, and ActionScript), VBScript, and bash (Bourne Again Shell).
Scripting languages can be used to learn basic operators: assigning values to variables " i=1 " (the variable named i is assigned the value 1); arithmetic statements i++, i--, i+=1, i-=1, i*=1; transitions if, switch, return, continue; cycles while, do while, for, loop; and implementing simple algorithms. The advantage of scripting languages is that if you manage to launch a console that supports the language, you can immediately write code in that language, and this code will be executed.
fork bomb
An example of a bash scripting program that can be executed on the Linux command line:
:(){ :|:& };:
In this construct, the ":" character is the function name. In well-designed programming languages, function names must begin with a letter of the English alphabet, but bash doesn't have such rules. Let's replace the colon with the letter "f":
f()
{
f | f &
};
f
A function without parameters is defined. In the function body (the body inside the curly braces):
f | f &
The function itself is called. In well-designed programming languages, parentheses are required after the function name f() when calling a function. Bash and most scripting languages don't require this. Even in high-level languages, the idea is "flexibility"—let the programmer decide whether to use parentheses or not. This doesn't add flexibility, as people don't use parentheses because of typos, forgetfulness, or because they copied code from somewhere without thinking about it (otherwise they would have added parentheses and made the code readable). And this code works.
Let's rewrite the function body with parentheses:
f() | f() &
The " | " symbol means that the result of executing the command on the left is passed to the command on the right. When the leftmost command is executed, recursion occurs. The function's call stack is exhausted, and the process terminates with an error. Although the function has no parameters, a recursive call stores the address to which control is transferred when the function exits (the "return address"), which wastes memory. This address is stored in memory organized as a stack (first-in, last-out), hence the name "call stack."
The " & " sign means - do not wait for the result of executing what is to the left of the " & " sign, fork a new process and continue execution.
This code causes the operating system to exhaust resources if they haven't been limited, hence the name "bomb." This causes the operating system to freeze or become inoperable. Less "malicious" code (without spawning a new process with the "&" symbol):
f(){ f|f;};f
or without the pipe symbol " | ", only with recursion:
f(){ f;};f
The execution of these programs can be stopped by closing the terminal in which these programs are running.
Esoteric (amazing) programming languages
Esoteric languages are those created to explore the limits of programming language design, to prove the feasibility of an idea, as works of software art, or as a joke. These languages are mostly invented for fun, often parodying real programming languages or being absurd embodiments of programming concepts. In practice, such languages are useless, but programming in some of them provides excellent training, which is why they are often included in the list of permitted languages in programming contests.
The first known esoteric language was created in 1972 and was called InterCAL. It was created by students as a parody of existing programming languages and as a mental exercise.
In 1993, the FALSE language was created so that a compiler could be written for it that was no more than one kilobyte in size, and to come up with a syntax that would look like encryption (a random set of characters).
To achieve this, the language uses exotic punctuation marks and eliminates spaces. An example of implementing the condition if (a>1) b=3; (if a is greater than 1, then assign b the value 1) in FALSE:
a;1>[3b:]?
It resembles a program in the bash scripting language, although bash is not considered an esoteric language.
The " ? " sign is the " if " operator. The " : " sign is an assignment. " 3b: " means to assign b the value 3 . The " = " sign is a comparison. The " ; " sign means to push the value of the variable onto the stack. One is compared with the value of the variable on the stack.
Stack-based programming languages
Stack-based programming languages use inverse postfix notation, in which the parameters of a command (operator) must be written before the command (operator) itself, with the first parameter placed to the right of the left. For example, the simple addition of two numbers " 1 + 2 " (which is scientifically called "infix notation") would be written as " 1 2 + " (inverse postfix notation). In prefix notation, the addition would look like " +1 2 " or " +(1 2) ". Parentheses make the expression clearer, but they have no purpose. The rule is: if the number of operands is fixed, parentheses are optional.
Stack-based languages are further removed from human languages, but closer to the machine implementation of working with memory cells (registers) using stack logic: push the number 2 into a memory cell (stack logic) , then take the number 1 and add it to what's in that memory cell. A processor can have one or more stacks with different data sizes.
Postfix notation is called Polish, as it was invented in 1920 by a Polish logician. The number of command parameters (operator operands, predicate arguments) is called N-arity. For example: a unary operator is an operator with one operand. For example, " a++ " is called postfix unary, meaning increment by one: " a=a+1 " or " a+=1 ". A binary operator is an operator with two operands. For example, the addition operator " a+b ". A ternary operator is an operator with three operands. For example, the conditional operator z=(x>y)?a:b is equivalent to:
if (x>y)
{
z=a;
}
else
{
z=b;
}
The ternary operator returns a value, while the if operator does not.
Stack-based languages are difficult for humans to write programs on, so they're not widely used. An example of a stack-based language is PostScript, which is used by printers. Here's an example of a PostScript program:
%!PS-Adobe-1.0
0 10 1 { % cycle from 0 to 10 in increments of 1
(Hello) show % print the word Hello
} for
showpage
In C, a similar program looks like this:
#include <stdio.h> //add the file where the puts function is described
int main(void) //function from which execution will begin
{
for(int i=0;i<=10;i++) //loop from 0 to 10 with step 1
{
puts("Hello"); //print Hello
}
}
The C language doesn't have many postfix and prefix operators, and they all have a single operand. Prefix operators were added to C, but they could have been omitted. Prefix operators are mostly needed so that teachers in computer science classes ask, "What's the difference between a prefix increment and a postfix increment?" Increment is an English word meaning increase, decrement means decrease, and multiplication means multiplication.
Example program in C language
A program that sorts numbers using the bubble sorting method.
Create a file named bubblesort.c
#include <stdio.h>
int main()
{
int a[]={3,5,4,1,2}; // array of numbers to sort
int n = sizeof(a)/sizeof(a[0]); // number of numbers in the array
for(int i=0; i<n-1; i++) // sort
{
for(int j=0; j<ni-1; j++) // compare adjacent array elements
{
if(a[j] > a[j+1]) // if the elements are not in order, swap them
{
int temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
for(int i=0; i<n; i++) // print the result
{
printf("%d ", a[i]);
}
printf("\n"); // print a carriage return character
return 0; // return the program execution status
}
Compile the created program with the command:
cc bubblesort.c -o bubblesort
Run the compiled program:
./bubblesort
1 2 3 4 5
Example program in PL/PgSQL
Let's look at what a program in an Ada language looks like. PL/PgSQL is similar to Ada syntax, but in Ada, arrays are denoted with parentheses rather than square brackets, which creates confusion and makes the program code difficult to read: arrays in Ada are easily confused with functions.
student:~$ psql
postgres=# CREATE OR REPLACE FUNCTION bubblesort(a int[])
RETURNS int[] AS
$$
DECLARE
n int = array_length(a, 1);
temp int;
begin
for i in 1..n loop
for j in 1..ni loop
if a[j] > a[j+1] then
temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
end if;
end loop;
end loop;
return a;
end;
$$ LANGUAGE plpgsql;
Executing the created function with the command select bubblesort(ARRAY[3,5,4,1,2]);
To create electrical circuits, hardware description languages are used: Verilog, based on the C language, and Verilog, based on the Ada language. Programs in these languages describe data processing actions. Data are electrical signals, and actions are operations such as NOR, AND, and XOR , which are implemented by elements of electrical circuits. A spatial diagram of electrical components and the conductive paths between them is generated from the program text. Layer diagrams are converted into images, from which photomasks can be created for etching paths on a silicon wafer using ultraviolet lithography. Photomasks are used because light has a short wavelength, which means high resolution. Currently, processors can be manufactured with a resolution of 2-5 nanometers. The Apple A16 processor is created with a resolution of 4 nanometers. Mass-market chips use processes with lower resolutions, as they are cheaper to produce. The ESP32 processor uses a resolution of 40 nanometers and has low power consumption. Transistor sizes are larger than the resolution, which determines the minimum interconnect size, not the transistor size. Therefore, as resolution improves, the spatial arrangement of transistors changes. Layout names include: VTFET, GAAFET, and FinFET. In a GAAFET (Gate-all-around) transistor, the gate completely surrounds the channel, while in a FinFET, it partially surrounds the channel.
What's next?
To learn how to work in Linux and programming, the book "Basics of Programming" can be useful, which can be found on the website http://stolyarov.info/
For those who want to study computer architecture and get acquainted with assembler https://teach-in.ru/course/architecture-and-assembler/about
If you don't have Linux installed on your computer, you can install Virtualbox https://www.virtualbox.org/wiki/Downloads and download a virtual machine image in the Open Virtual Appliance (OVA) format (configuration) https://disk.360.yandex.ru/d/eUu522ezEGuXvA , which allows you to directly write, compile, and run C programs. It's also convenient to install the Eclipse IDE for C/C++ Developers development environment https://www.eclipse.org/downloads/packages/ in the virtual machine . You might be able to handle the installation.